This page documents the detailed steps to load CSV file from GCS into BigQuery using Dataflow to demo a simple data flow creation using Dataflow Tools for Eclipse. However it doesn’t necessarily mean this is the right use case for DataFlow.
Alternatively bq command line or programming APIs (Java, .NET, Python, Ruby, GO, etc.) can be used to ingest data into BigQuery; files in GCS can also be mapped directly as external table in BigQuery.
Prerequisites
- Eclipse 4.6 +
- JDK 1.8+
- GCP account
- GCS and BigQuery enabled
- Service account
For my environment, I am using Eclipse Photon Release (4.8.0). Make sure the Eclipse installation path has not space, otherwise you may encounter the following error:

Detailed steps
Install Cloud SDK
Follow this page to install Cloud SDK.
Install Cloud Tools for Eclipse
Install Cloud Tools for Eclipse by following this page:
*Cloud developer tools are also available for other IDEs, incl. InteliJ, Visual Studio, ISE, PowerShell, etc.
Create a DataFlow project
Create a new project through New Project wizard.
Select Google Cloud Dataflow Java Project wizard. Click Next to continue.
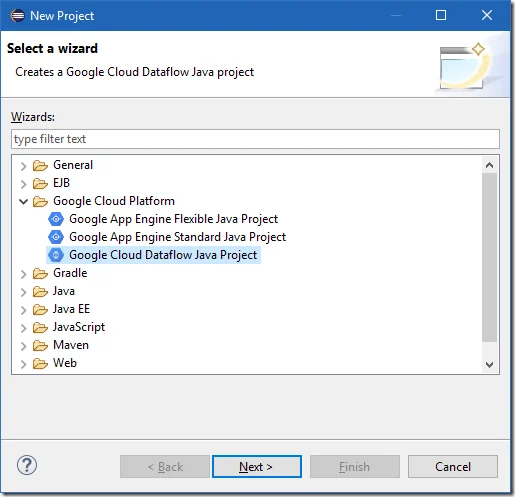
Input the details for this project:
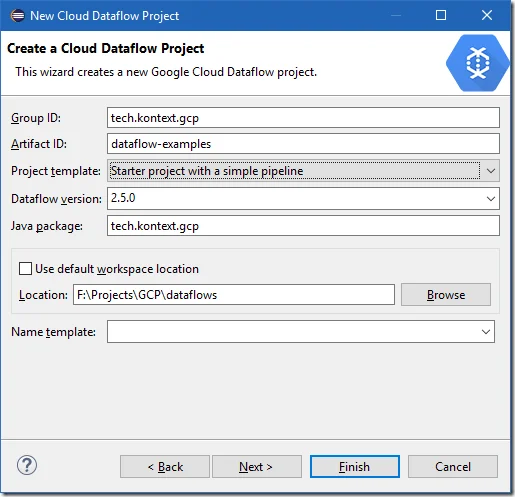
Setup account details:
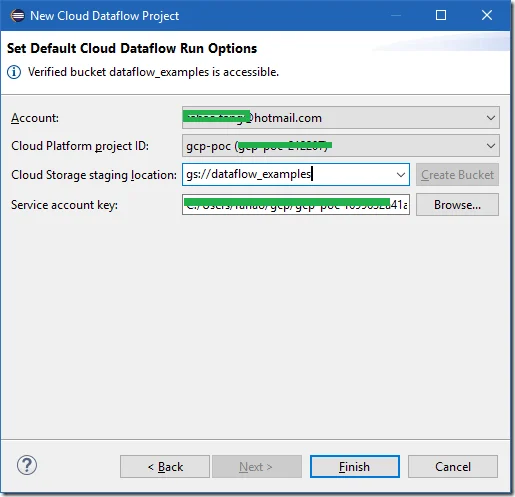
Click Finish to complete the wizard.
Build the project
Run Maven Install to install the dependencies. You can do this through Run Configurations or Maven command line interfaces.
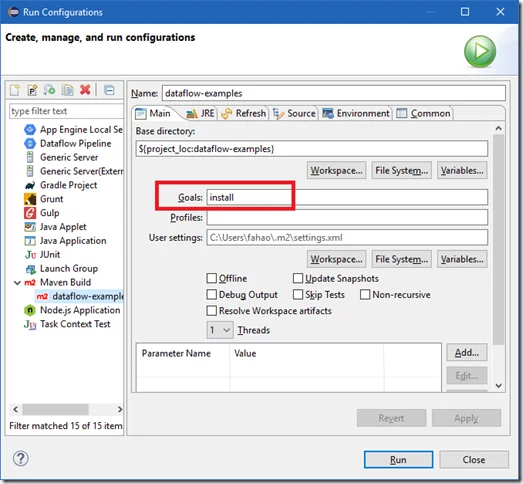
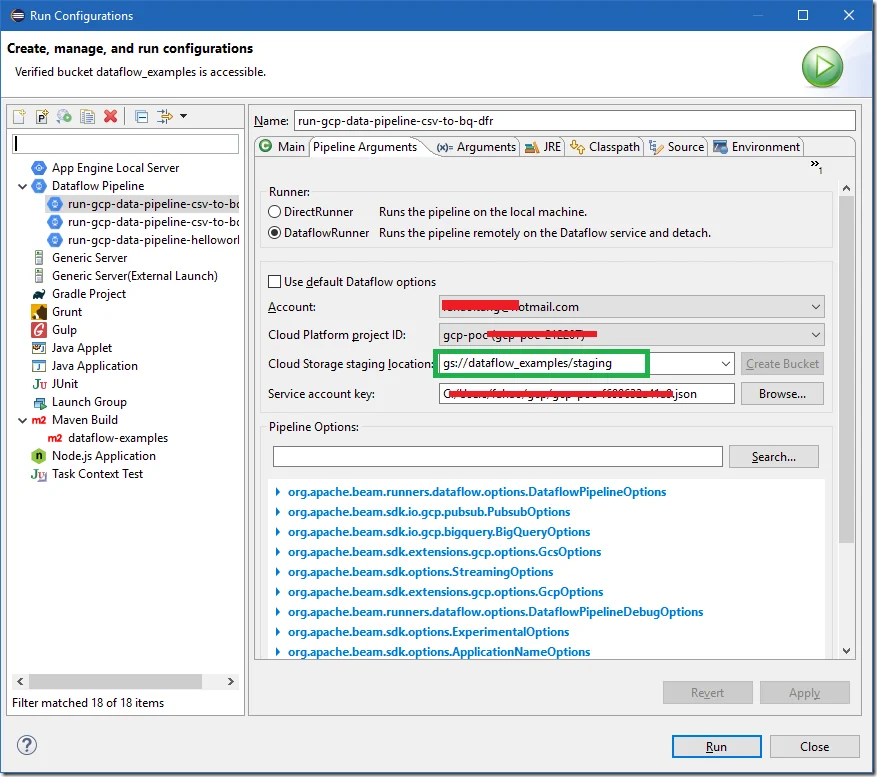
Once build is successful, you can create a run configuraiton for Dataflow pipeline:
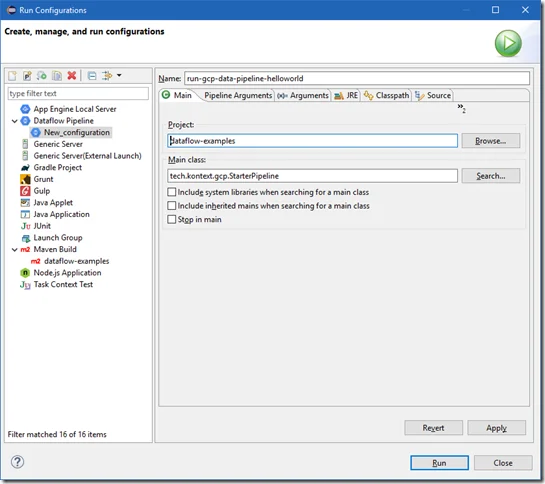
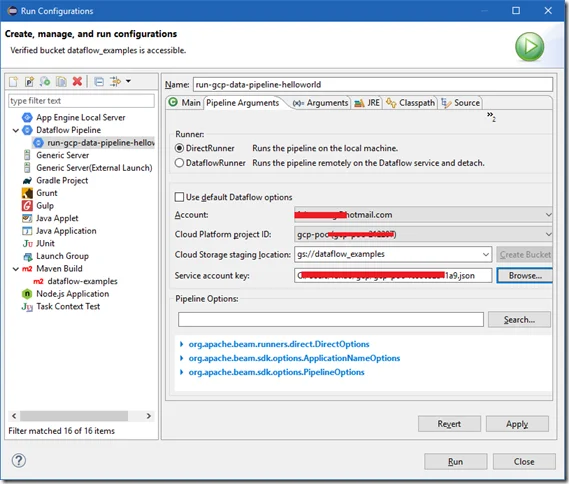
For Pipeline Arguments tab, choose Direct Runner for now.
The output of the result will show in Console:

Create a pipeline to load CSV file in GCS to BigQuery
Create a sample file named sample.csv with the following content:
ID,Code,Value,Date 1,A,200.05,2017-01-01 2,B,300.05,2017-02-01 3,C,400.05,2017-03-01 4,D,500.05,2017-04-01
Upload the file into a bucket. For example, dataflow_examples/sample.csv
Copy the StarterPipeline class to create a new one named CsvToBQPipeline.
Refer to the sample data flows: https://github.com/apache/beam/blob/master/examples/java/src/main/java/org/apache/beam/examples/complete/AutoComplete.java.
For this demo purpose, create the class with the following content:
/* * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package tech.kontext.gcp;import java.io.IOException; import java.util.ArrayList; import java.util.Arrays; import java.util.List;import org.apache.beam.runners.dataflow.DataflowRunner; import org.apache.beam.runners.dataflow.options.DataflowPipelineOptions; import org.apache.beam.sdk.Pipeline; import org.apache.beam.sdk.io.TextIO; import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO; import org.apache.beam.sdk.options.PipelineOptions; import org.apache.beam.sdk.options.PipelineOptionsFactory; import org.apache.beam.sdk.transforms.Create; import org.apache.beam.sdk.transforms.DoFn; import org.apache.beam.sdk.transforms.MapElements; import org.apache.beam.sdk.transforms.ParDo; import org.apache.beam.sdk.transforms.SimpleFunction; import org.slf4j.Logger; import org.slf4j.LoggerFactory;import com.google.api.services.bigquery.model.TableReference; import com.google.api.services.bigquery.model.TableRow; import com.google.api.services.bigquery.model.TableSchema; import com.google.api.services.bigquery.model.TableFieldSchema;/** * A starter example for writing Beam programs. * * <p> * The example takes two strings, converts them to their upper-case * representation and logs them. * * <p> * To run this starter example locally using DirectRunner, just execute it * without any additional parameters from your favorite development environment. * * <p> * To run this starter example using managed resource in Google Cloud Platform, * you should specify the following command-line options: * --project=<YOUR_PROJECT_ID> * --stagingLocation=<STAGING_LOCATION_IN_CLOUD_STORAGE> --runner=DataflowRunner */ public class CsvToBQPipeline { private static final Logger LOG = LoggerFactory.getLogger(CsvToBQPipeline.class); private static String HEADERS = "ID,Code,Value,Date"; public static class FormatForBigquery extends DoFn<String, TableRow> { private String[] columnNames = HEADERS.split(","); @ProcessElement public void processElement(ProcessContext c) { TableRow row = new TableRow(); String[] parts = c.element().split(","); if (!c.element().contains(HEADERS)) { for (int i = 0; i < parts.length; i++) { // No typy conversion at the moment. row.set(columnNames[i], parts[i]); } c.output(row); } } /** Defines the BigQuery schema used for the output. */ static TableSchema getSchema() { List<TableFieldSchema> fields = new ArrayList<>(); // Currently store all values as String fields.add(new TableFieldSchema().setName("ID").setType("STRING")); fields.add(new TableFieldSchema().setName("Code").setType("STRING")); fields.add(new TableFieldSchema().setName("Value").setType("STRING")); fields.add(new TableFieldSchema().setName("Date").setType("STRING")); return new TableSchema().setFields(fields); } } public static void main(String[] args) throws Throwable { // Currently hard-code the variables, this can be passed into as parameters String sourceFilePath = "gs://dataflow_examples/sample.csv"; String tempLocationPath = "gs://poc-dataflow-temp/bq"; boolean isStreaming = false; TableReference tableRef = new TableReference(); // Replace this with your own GCP project id tableRef.setProjectId("gcp-project-id"); tableRef.setDatasetId("sample_ds"); tableRef.setTableId("sample"); PipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().create(); // This is required for BigQuery options.setTempLocation(tempLocationPath); options.setJobName("csvtobq"); Pipeline p = Pipeline.create(options); p.apply("Read CSV File", TextIO.read().from(sourceFilePath)) .apply("Log messages", ParDo.of(new DoFn<String, String>() { @ProcessElement public void processElement(ProcessContext c) { LOG.info("Processing row: " + c.element()); c.output(c.element()); } })).apply("Convert to BigQuery TableRow", ParDo.of(new FormatForBigquery())) .apply("Write into BigQuery", BigQueryIO.writeTableRows().to(tableRef).withSchema(FormatForBigquery.getSchema()) .withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED) .withWriteDisposition(isStreaming ? BigQueryIO.Write.WriteDisposition.WRITE_APPEND : BigQueryIO.Write.WriteDisposition.WRITE_TRUNCATE)); p.run().waitUntilFinish(); } }
And then run the code through local DirectRunner (set through Pipeline Arguments tab).
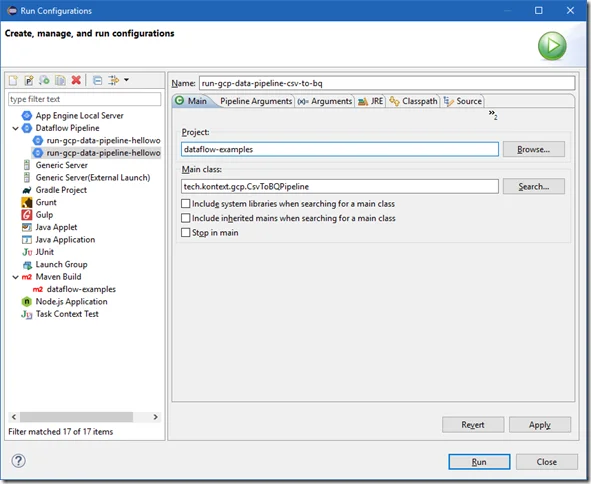
You may get errors like the following if your temp location is different from your BigQuery location:
"errorResult" : { "message" : "Cannot read and write in different locations: source: asia, destination: asia-northeast1", "reason" : "invalid" }
The logs will also be printed to the Output window of Eclipse:
View the job in Console
You can also run through DataflowRunner (set through Pipeline Arguments tab). The job will then be uploaded into Dataflow in GCP.
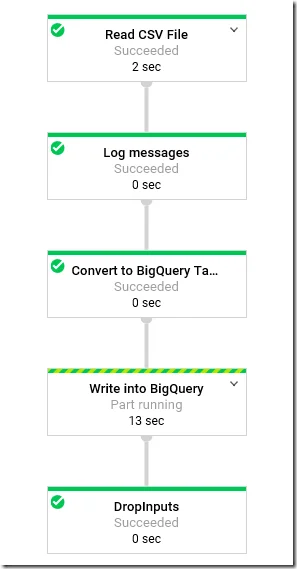
View the jobs status through cloud SDK shell
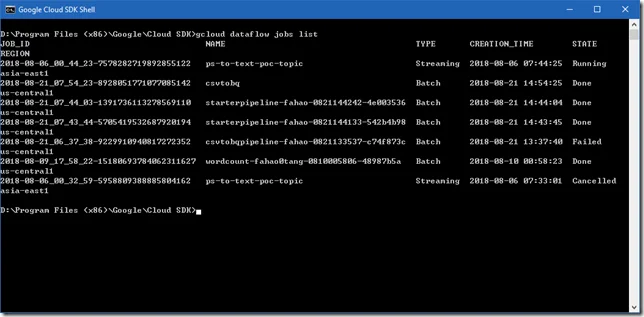
Run the following command in Cloud SDK Shell or Client Tools for PowerShell:
gcloud dataflow jobs list
The result will be similar as the followings:
{kind=link}
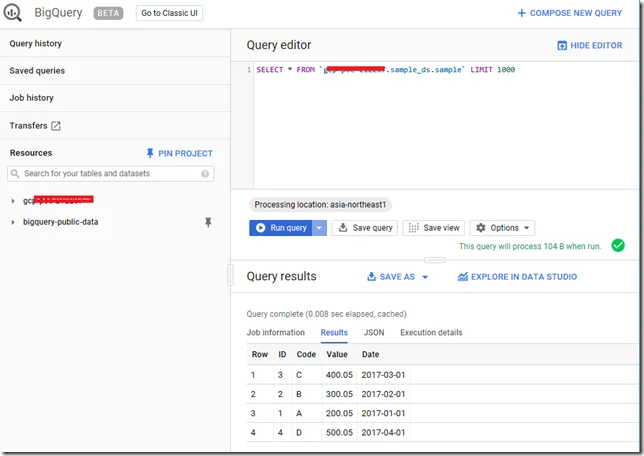
Verify the result in BigQuery
Once data is loaded, you can run the following query to query it:
SELECT * FROM `gcp-project-id.sample_ds.sample` LIMIT 1000
Remember to change the project ID.
Error debugs
Exception in thread "main" java.lang.RuntimeException: Failed to construct instance from factory method DataflowRunner#fromOptions
To resolve this issue, set the staging location to a folder in a bucket: