In this page, I’m going to demonstrate how to write and read parquet files in Spark/Scala by using Spark SQLContext class.
Reference
What is parquet format?
Go the following project site to understand more about parquet.
Prerequisites
Spark
If you have not installed Spark, follow this page to setup:
Install Big Data Tools (Spark, Zeppelin, Hadoop) in Windows for Learning and Practice
Hadoop (Optional)
In this example, I am going to read CSV files in HDFS. You can setup your local Hadoop instance via the same above link.
Alternatively, you can change the file path to a local file.
IntelliJ IDEA
I am using IntelliJ to write the Scala script. You can also use Scala shell to test instead of using IDE. Scala SDK is also required. In my case, I am using the Scala SDK distributed as part of my Spark.
JDK
JDK is required to run Scala in JVM.
Read and Write parquet files
In this example, I am using Spark SQLContext object to read and write parquet files.
Code
import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.sql.{DataFrame, SQLContext}object ParquetTest { def main(args: Array[String]) = { // Two threads local[2] val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("ParquetTest") val sc: SparkContext = new SparkContext(conf) val sqlContext: SQLContext = new SQLContext(sc) writeParquet(sc, sqlContext) readParquet(sqlContext) } def writeParquet(sc: SparkContext, sqlContext: SQLContext) = { // Read file as RDD val rdd = sqlContext.read.format("csv").option("header", "true").load("hdfs://0.0.0.0:19000/Sales.csv") // Convert rdd to data frame using toDF; the following import is required to use toDF function. val df: DataFrame = rdd.toDF() // Write file to parquet df.write.parquet("Sales.parquet") } def readParquet(sqlContext: SQLContext) = { // read back parquet to DF val newDataDF = sqlContext.read.parquet("Sales.parquet") // show contents newDataDF.show() }}
Before you run the code
Make sure IntelliJ project has all the required SDKs and libraries setup. In my case
- JDK is using 1.8 JDK installed in my C drive.
- Scala SDK: version 2.11.8 as part of my Spark installation (spark-2.2.1-bin-hadoop2.7)
- Jars: all libraries in my Spark jar folder (for Spark libraries used in the sample code).
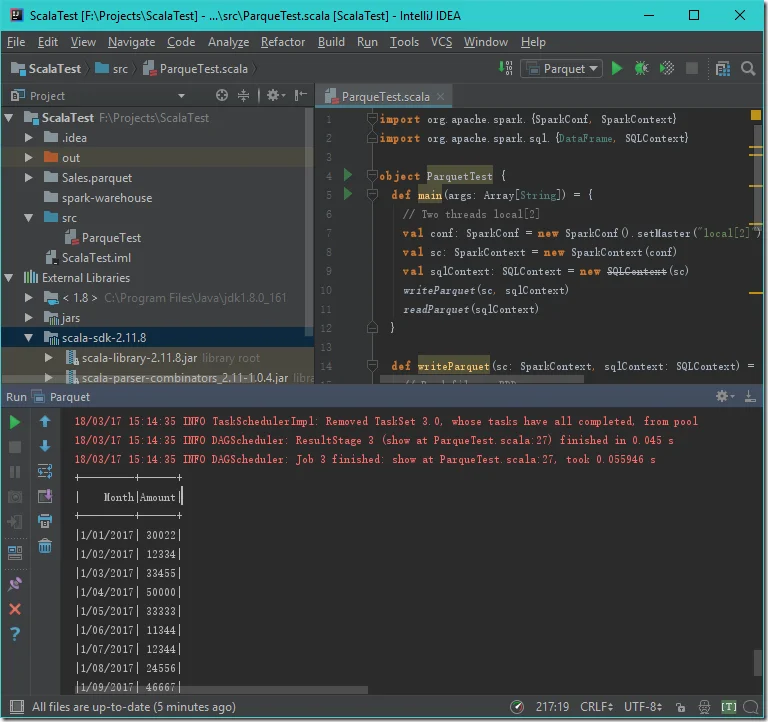
Run the code in IntelliJ
The following is the screenshot for the output:
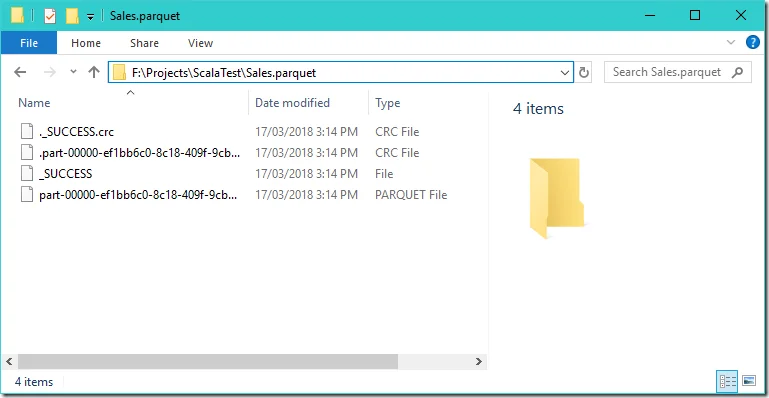
What was created?
In the example code, a local folder Sales.parquet is created:
Run the code in Zeppelin
You can also run the same code in Zeppelin. If you don’t have a Zeppelin instance to play with, you can follow the same link in the Prerequisites section to setup.