In my previous post, I demonstrated how to write and read parquet files in Spark/Scala. The parquet file destination is a local folder.
Write and Read Parquet Files in Spark/Scala
In this page, I am going to demonstrate how to write and read parquet files in HDFS.
Sample code
import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.sql.{DataFrame, SQLContext}object ParquetTest { def main(args: Array[String]) = { // Two threads local[2] val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("ParquetTest") val sc: SparkContext = new SparkContext(conf) val sqlContext: SQLContext = new SQLContext(sc) writeParquet(sc, sqlContext) readParquet(sqlContext) } def writeParquet(sc: SparkContext, sqlContext: SQLContext) = { // Read file as RDD val rdd = sqlContext.read.format("csv").option("header", "true").load("hdfs://0.0.0.0:19000/Sales.csv") // Convert rdd to data frame using toDF; the following import is required to use toDF function. val df: DataFrame = rdd.toDF() // Write file to parquet df.write.parquet("hdfs://0.0.0.0:19000/Sales.parquet"); } def readParquet(sqlContext: SQLContext) = { // read back parquet to DF val newDataDF = sqlContext.read.parquet("hdfs://0.0.0.0:19000/Sales.parquet") // show contents newDataDF.show() }}
The output should be similar to the previous example.
View the parquet files in HDFS
The following command can be used to list the parquet files:
F:\DataAnalytics\hadoop-3.0.0\sbin>hdfs dfs -ls / Found 4 items -rw-r--r-- 1 fahao supergroup 167 2018-02-26 14:42 /Sales.csv drwxr-xr-x - fahao supergroup 0 2018-03-17 15:44 /Sales.parquet -rw-r--r-- 1 fahao supergroup 167 2018-02-26 14:11 /Sales2.csv -rw-r--r-- 1 fahao supergroup 9 2018-02-19 22:18 /test.txt
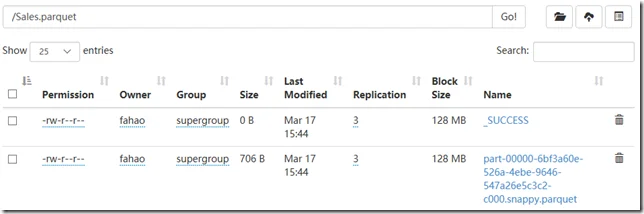
You can also use the HDFS website portal to view it:
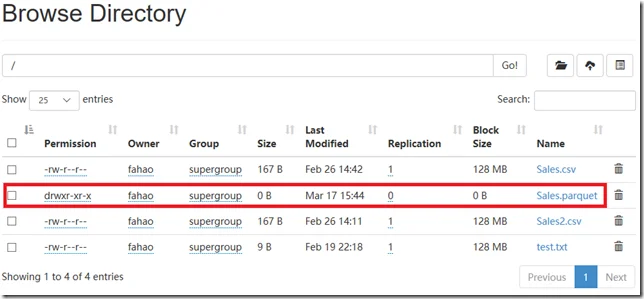
Navigate into the parquet folder: