The page summarizes the steps required to run and debug PySpark (Spark for Python) in Visual Studio Code.
Install Python and pip
Install Python from the official website:
The version I am using is 3.6.4 32-bit. Pip is shipped together in this version.
Install Spark standalone edition
Download Spark 2.3.3 from the following page:
https://www.apache.org/dyn/closer.lua/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
If you don’t know how to install, please follow the following page:
*Remember to change the package to version 2.3.3.
There is one bug with the latest Spark version 2.4.0 and thus I am using 2.3.3.
Install pyspark package
Since Spark version is 2.3.3, we need to install the same version for pyspark via the following command:
pip install pyspark==2.3.3
The version needs to be consistent otherwise you may encounter errors for package py4j.
Run PySpark code in Visual Studio Code
You can run PySpark through context menu item Run Python File in Terminal.
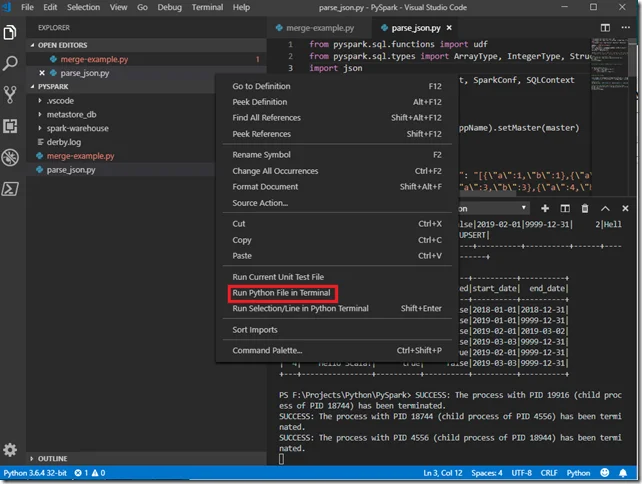
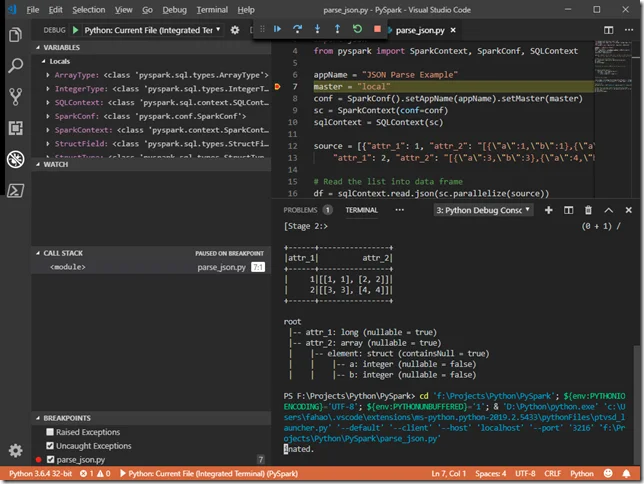
Alternatively, you can also debug your application in VS Code too as shown in the following screenshot:
Run Azure HDInsights PySpark code
You can install extension Azure HDInsight Tools to submit spark jobs in VS Code to your HDInsights cluster.
For more details, refer to the extension page:
https://marketplace.visualstudio.com/items?itemName=mshdinsight.azure-hdinsight