In my previous post about Data Partitioning in Spark (PySpark) In-depth Walkthrough, I mentioned how to repartition data frames in Spark using repartition or coalesce functions.
In this post, I am going to explain how Spark partition data using partitioning functions.
Partitioner
Partitioner class is used to partition data based on keys. It accepts two parameters numPartitions and partitionFunc to initiate as the following code shows:
def __init__(self, numPartitions, partitionFunc):
The first parameter defines the number of partitions while the second parameter defines the partition function.
def __call__(self, k):
return self.partitionFunc(k) % self.numPartitions
Partitioner then uses this partition function to generate the partition number for each keys.
partitionBy function
The partitionBy function is defined as the following:
def partitionBy(self, numPartitions, partitionFunc=portable_hash)
By default, the partition function is portable_hash.
Walkthrough with data
Create a sample data frame
Let’s first create a data frame using the following code:
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
from pyspark.rdd import portable_hash
from pyspark import Row
appName = "PySpark Partition Example"
master = "local[8]"
# Create Spark session with Hive supported.
spark = SparkSession.builder \
.appName(appName) \
.master(master) \
.getOrCreate()
print(spark.version)
spark.sparkContext.setLogLevel("ERROR")
# Populate sample data
countries = ("CN", "AU", "US")
data = []
for i in range(1, 13):
data.append({"ID": i, "Country": countries[i % 3], "Amount": 10+i})
def print_partitions(df):
numPartitions = df.rdd.getNumPartitions()
print("Total partitions: {}".format(numPartitions))
print("Partitioner: {}".format(df.rdd.partitioner))
df.explain()
parts = df.rdd.glom().collect()
i = 0
j = 0
for p in parts:
print("Partition {}:".format(i))
for r in p:
print("Row {}:{}".format(j, r))
j = j+1
i = i+1
df = spark.createDataFrame(data)
df.show()
print_partitions(df)
In the above code, print_partitions function will print out all the details about the RDD partitions including the rows in each partition.
There are 12 records populated:
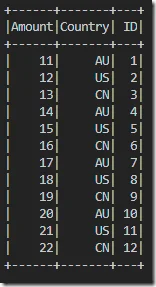
The output from print_partitions function is shown below:
Total partitions: 8 Partitioner: None == Physical Plan == Scan ExistingRDD[Amount#0L,Country#1,ID#2L] Partition 0: Row 0:Row(Amount=11, Country='AU', ID=1) Partition 1: Row 1:Row(Amount=12, Country='US', ID=2) Row 2:Row(Amount=13, Country='CN', ID=3) Partition 2: Row 3:Row(Amount=14, Country='AU', ID=4) Partition 3: Row 4:Row(Amount=15, Country='US', ID=5) Row 5:Row(Amount=16, Country='CN', ID=6) Partition 4: Row 6:Row(Amount=17, Country='AU', ID=7) Partition 5: Row 7:Row(Amount=18, Country='US', ID=8) Row 8:Row(Amount=19, Country='CN', ID=9) Partition 6: Row 9:Row(Amount=20, Country='AU', ID=10) Partition 7: Row 10:Row(Amount=21, Country='US', ID=11) Row 11:Row(Amount=22, Country='CN', ID=12)
Records are divided into 8 partitions as 8 worker threads were configured.
Repartition data
Let’s repartition the data to three partitions only by Country column.
numPartitions = 3
df = df.repartition(numPartitions, "Country")
print_partitions(df)
The output looks like the following:
Total partitions: 3 Partitioner: None == Physical Plan == Exchange hashpartitioning(Country#1, 3) +- Scan ExistingRDD[Amount#0L,Country#1,ID#2L] Partition 0: Partition 1: Row 0:Row(Amount=12, Country='US', ID=2) Row 1:Row(Amount=13, Country='CN', ID=3) Row 2:Row(Amount=15, Country='US', ID=5) Row 3:Row(Amount=16, Country='CN', ID=6) Row 4:Row(Amount=18, Country='US', ID=8) Row 5:Row(Amount=19, Country='CN', ID=9) Row 6:Row(Amount=21, Country='US', ID=11) Row 7:Row(Amount=22, Country='CN', ID=12) Partition 2: Row 8:Row(Amount=11, Country='AU', ID=1) Row 9:Row(Amount=14, Country='AU', ID=4) Row 10:Row(Amount=17, Country='AU', ID=7) Row 11:Row(Amount=20, Country='AU', ID=10)
You may expect that each partition includes data for each Country but that is not the case. Why? Because repartition function by default uses hash partitioning. For different country code, it may be allocated into the same partition number.
We can verify this by using the following code to calculate the hash
udf_portable_hash = udf(lambda str: portable_hash(str))
df = df.withColumn("Hash#", udf_portable_hash(df.Country))
df = df.withColumn("Partition#", df["Hash#"] % numPartitions)
df.show()
The output looks like the following:
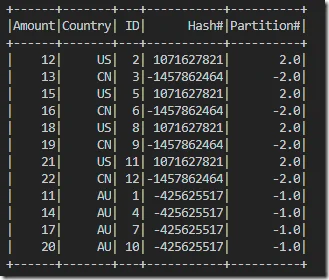
This output is consistent with the previous one as record ID 1,4,7,10 are allocated to one partition while the others are allocated to another question. There is also one partition with empty content as no records are allocated to that partition.
Allocate one partition for each key value
For the above example, if we want to allocate one partition for each Country (CN, US, AU), what should we do?
Well, the first thing we can try is to increase the partition number. In this way, the chance for allocating each different value to different partition is higher.
So if we increate the partition number to 5.
numPartitions = 5
df = df.repartition(numPartitions, "Country")
print_partitions(df)
udf_portable_hash = udf(lambda str: portable_hash(str))
df = df.withColumn("Hash#", udf_portable_hash(df.Country))
df = df.withColumn("Partition#", df["Hash#"] % numPartitions)
df.show()
The output shows that each country’s data is now located in the same partition:
Total partitions: 5 Partitioner: None == Physical Plan == Exchange hashpartitioning(Country#1, 5) +- Scan ExistingRDD[Amount#0L,Country#1,ID#2L] Partition 0: Partition 1: Partition 2: Row 0:Row(Amount=12, Country='US', ID=2) Row 1:Row(Amount=15, Country='US', ID=5) Row 2:Row(Amount=18, Country='US', ID=8) Row 3:Row(Amount=21, Country='US', ID=11) Partition 3: Row 4:Row(Amount=13, Country='CN', ID=3) Row 5:Row(Amount=16, Country='CN', ID=6) Row 6:Row(Amount=19, Country='CN', ID=9) Row 7:Row(Amount=22, Country='CN', ID=12) Partition 4: Row 8:Row(Amount=11, Country='AU', ID=1) Row 9:Row(Amount=14, Country='AU', ID=4) Row 10:Row(Amount=17, Country='AU', ID=7) Row 11:Row(Amount=20, Country='AU', ID=10) +------+-------+---+-----------+----------+ |Amount|Country| ID| Hash#|Partition#| +------+-------+---+-----------+----------+ | 12| US| 2| 1071627821| 1.0| | 15| US| 5| 1071627821| 1.0| | 18| US| 8| 1071627821| 1.0| | 21| US| 11| 1071627821| 1.0| | 13| CN| 3|-1457862464| -4.0| | 16| CN| 6|-1457862464| -4.0| | 19| CN| 9|-1457862464| -4.0| | 22| CN| 12|-1457862464| -4.0| | 11| AU| 1| -425625517| -2.0| | 14| AU| 4| -425625517| -2.0| | 17| AU| 7| -425625517| -2.0| | 20| AU| 10| -425625517| -2.0| +------+-------+---+-----------+----------+
However, what if the hashing algorithm generates the same hash code/number?
Use partitionBy function
To address the above issue, we can create a customised partitioning function.
At the moment in PySpark (my Spark version is 2.3.3) , we cannot specify partition function in repartition function. So we can only use this function with RDD class.
As partitionBy function requires data to be in key/value format, we need to also transform our data.
We can run the following code to use a custom paritioner:
def country_partitioning(k):
return countries.index(k)
udf_country_hash = udf(lambda str: country_partitioning(str))
df = df.rdd \
.map(lambda el: (el["Country"], el)) \
.partitionBy(numPartitions, country_partitioning) \
.toDF()
print_partitions(df)
df = df.withColumn("Hash#", udf_country_hash(df[0]))
df = df.withColumn("Partition#", df["Hash#"] % numPartitions)
df.show()
The output looks like the following:
Total partitions: 5 Partitioner: None == Physical Plan == Scan ExistingRDD[_1#17,_2#18] Partition 0: Row 0:Row(_1='CN', _2=Row(Amount=13, Country='CN', ID=3)) Row 1:Row(_1='CN', _2=Row(Amount=16, Country='CN', ID=6)) Row 2:Row(_1='CN', _2=Row(Amount=19, Country='CN', ID=9)) Row 3:Row(_1='CN', _2=Row(Amount=22, Country='CN', ID=12)) Partition 1: Row 4:Row(_1='AU', _2=Row(Amount=11, Country='AU', ID=1)) Row 5:Row(_1='AU', _2=Row(Amount=14, Country='AU', ID=4)) Row 6:Row(_1='AU', _2=Row(Amount=17, Country='AU', ID=7)) Row 7:Row(_1='AU', _2=Row(Amount=20, Country='AU', ID=10)) Partition 2: Row 8:Row(_1='US', _2=Row(Amount=12, Country='US', ID=2)) Row 9:Row(_1='US', _2=Row(Amount=15, Country='US', ID=5)) Row 10:Row(_1='US', _2=Row(Amount=18, Country='US', ID=8)) Row 11:Row(_1='US', _2=Row(Amount=21, Country='US', ID=11)) Partition 3: Partition 4: +---+------------+-----+----------+ | _1| _2|Hash#|Partition#| +---+------------+-----+----------+ | CN| [13, CN, 3]| 0| 0.0| | CN| [16, CN, 6]| 0| 0.0| | CN| [19, CN, 9]| 0| 0.0| | CN|[22, CN, 12]| 0| 0.0| | AU| [11, AU, 1]| 1| 1.0| | AU| [14, AU, 4]| 1| 1.0| | AU| [17, AU, 7]| 1| 1.0| | AU|[20, AU, 10]| 1| 1.0| | US| [12, US, 2]| 2| 2.0| | US| [15, US, 5]| 2| 2.0| | US| [18, US, 8]| 2| 2.0| | US|[21, US, 11]| 2| 2.0| +---+------------+-----+----------+
Through this customised partitioning function, we guarantee each different country code gets a unique deterministic hash number.
Now if we change the number of partitions to 2, both US and CN records will be allocated to one partition because:
- CN (Hash# = 0): 0%2 = 0
- US (Hash# = 2): 2%2 = 0
- AU (Hash# = 1): 1%2 = 1
Let’s keep exploring a little bit more.
For the above partitioned data frame (2 partitions), if we then write the dataframe to file system, how many sharded files will be generated?
df = df.select(df["_1"].alias("Country"), df["Hash#"], df["Partition#"],
df["_2"]["Amount"].alias("Amount"), df["_2"]["ID"].alias("ID"))
df.show()
print_partitions(df)
df.write.mode("overwrite").partitionBy("Country").csv("data/example2.csv", header=True)
The answer is 2 as there are two partitions.
The first file includes data for country CN and US and the other one includes data for country AU.
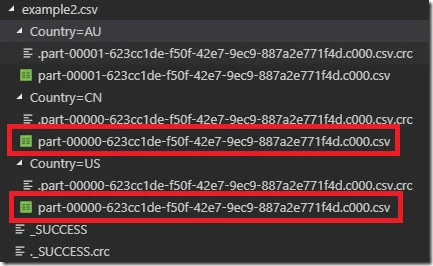
However, if we change the last line of code to the follow:
df.write.mode("overwrite").partitionBy("Country").csv("data/example2.csv", header=True)
Then three folders will be created with one file in each. The partition number for CN and US folders will be the same since the data is from the same partition.
Scala / Java
For this post, I am only focusing on PySpark, if you primarily use Scala or Java, the concepts are similar. For example, in Scala/Java APIs, you can also implement a customised Partitioner class to customise your partition strategy.
If you have any questions, feel free to comment here.