Spark 3.0.0 was release on 18th June 2020 with many new features. The highlights of features include adaptive query execution, dynamic partition pruning, ANSI SQL compliance, significant improvements in pandas APIs, new UI for structured streaming, up to 40x speedups for calling R user-defined functions, accelerator-aware scheduler and SQL reference documentation.
This article summarizes the steps to install Spark 3.0 on your Windows 10 environment.
Tools and Environment
- GIT Bash
- Command Prompt
- Windows 10
- Python
- Java JDK
Install Git Bash
Download the latest Git Bash tool from this page: https://git-scm.com/downloads.
Run the installation wizard to complete the installation.
Install Java JDK
Spark 3.0 runs on Java 8/11. You can install Java JDK 8 based on the following section.
Step 4 - (Optional) Java JDK installation
If Java 8/11 is available in your system, you don't need install it again.
Install Python
Python is required for using PySpark. Follow these steps to install Python.
- Download and install python from this web page: https://www.python.org/downloads/.https://www.python.org/downloads/

- Verify installation by running the following command in Command Prompt or PowerShell:
python --version
The output looks like the following:

If python command cannot be directly invoked, please check PATHenvironment variable to make sure Python installation path is added:
For example, in my environment Python is installed at the following location:

Thus path C:\Users\Raymond\AppData\Local\Programs\Python\Python38-32 is added to PATH variable.

Hadoop installation (optional)
To work with Hadoop, you can configure a Hadoop single node cluster following this article:
Install Hadoop 3.3.0 on Windows 10 Step by Step Guide
Download binary package
Go to the following site:
https://spark.apache.org/downloads.htmlhttps://spark.apache.org/downloads.html
Select the package type accordingly. I already have Hadoop 3.3.0 installed in my system, thus I selected the following:

You can choose the package with pre-built for Hadoop 3.2 or later.

Save the latest binary to your local drive. In my case, I am saving the file to folder: F:\big-data. If you are saving the file into a different location, remember to change the path in the following steps accordingly.
Unpack binary package
Open Git Bash, and change directory (cd) to the folder where you save the binary package and then unzip using the following commands:
$ mkdir spark-3.0.0
$ tar -C spark-3.0.0 -xvzf spark-3.0.0-bin-without-hadoop.tgz --strip 1
The first command creates a sub folder named spark-3.0.0; the second command unzip the downloaded package to that folder.
warning Your file name might be different from spark-3.0.0-bin-without-hadoop.tgz if you chose a package with pre-built Hadoop libs.
Spark 3.0 files are now extracted to F:\big-data\spark-3.0.0.
Setup environment variables
- Setup JAVA_HOMEvariable.
Setup environment variable JAVA_HOME if it is not done yet. The variable value points to your Java JDK location.

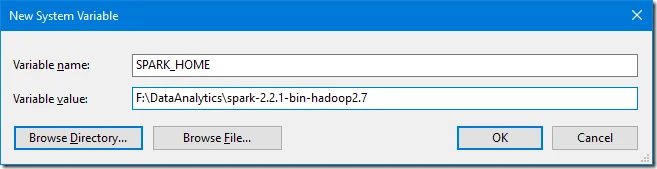
- Setup SPARK_HOME variable.
Setup SPARK_HOMEenvironment variable with value of your spark installation directory.

- Update PATH variable.
Added ‘%SPARK_HOME%\bin’ to your PATHenvironment variable.

- Configure Spark variableSPARK_DIST_CLASSPATH.
This is only required if you configure Spark with an existing Hadoop. If your package type already includes pre-built Hadoop libraries, you don't need to do this.
Run the following command in Command Prompt to find out existing Hadoop classpath:
F:\big-data>hadoop classpath
F:\big-data\hadoop-3.3.0\etc\hadoop;F:\big-data\hadoop-3.3.0\share\hadoop\common;F:\big-data\hadoop-3.3.0\share\hadoop\common\lib\*;F:\big-data\hadoop-3.3.0\share\hadoop\common\*;F:\big-data\hadoop-3.3.0\share\hadoop\hdfs;F:\big-data\hadoop-3.3.0\share\hadoop\hdfs\lib\*;F:\big-data\hadoop-3.3.0\share\hadoop\hdfs\*;F:\big-data\hadoop-3.3.0\share\hadoop\yarn;F:\big-data\hadoop-3.3.0\share\hadoop\yarn\lib\*;F:\big-data\hadoop-3.3.0\share\hadoop\yarn\*;F:\big-data\hadoop-3.3.0\share\hadoop\mapreduce\*
Setup an environment variable SPARK_DIST_CLASSPATH accordingly using the output:

Config Spark default variables
Run the following command to create a default configuration file:
cp %SPARK_HOME%/conf/spark-defaults.conf.template %SPARK_HOME%/conf/spark-defaults.conf
Open spark-defaults.conf file and add the following entries:
spark.driver.host localhost
Now Spark is available to use.
Verify the installation
Let's run some verification to ensure the installation is completed without errors.
Verify spark-shell command
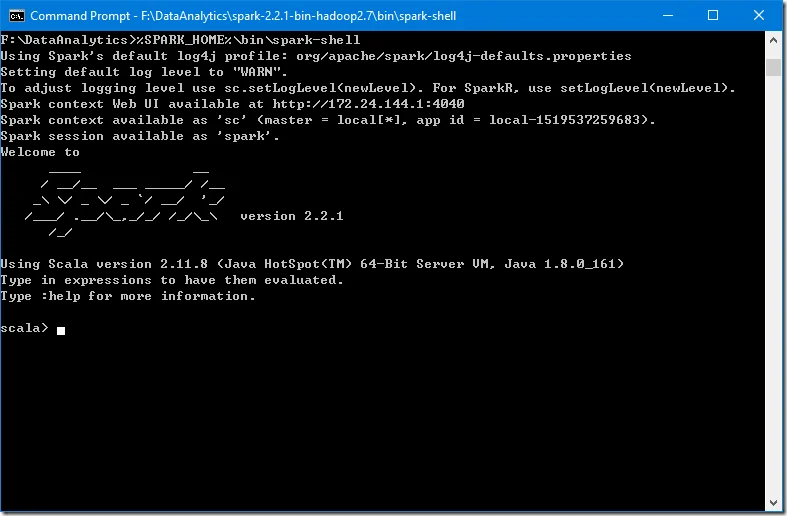
Run the following command in Command Prompt to verify the installation.
spark-shell
The screen should be similar to the following screenshot:

You can use Scala in this interactive window.
Run examples
Execute the following command in Command Prompt to run one example provided as part of Spark installation (class SparkPi with param 10).
https://spark.apache.org/docs/latest/
%SPARK_HOME%\bin\run-example.cmd SparkPi 10
The output looks like the following:

PySpark interactive window
Run the following command to try PySpark:
pyspark

Python in my environment is 3.8.2.
Try Spark SQL
Spark SQL interactive window can be run through this command:
spark-sql
As I have not configured Hive in my system, thus there will be error when I run the above command.
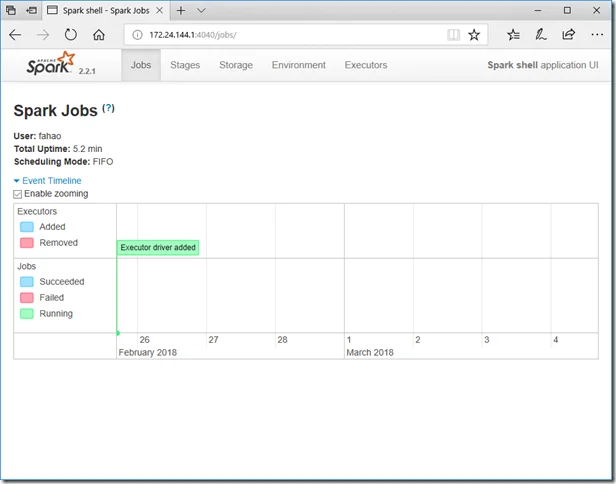
Spark context UI
When a Spark session is running, you can view the details through UI portal. As printed out in the interactive session window, Spark context Web UI available at http://localhost:4040. The URL is based on the Spark default configurations. The port number can change if the default port is used.
The following is a screenshot of the UI:

References
Spark developer tools
Refer to the following page if you are interested in any Spark developer tools.
https://spark.apache.org/developer-tools.htmlhttps://spark.apache.org/developer-tools.html
Spark 3.0.0 overview
Refer to the official documentation about Spark 3.0.0 overview: http://spark.apache.org/docs/3.0.0/.
Spark 3.0.0 release notes
https://spark.apache.org/releases/spark-release-3-0-0.html
check Congratulations! You have successfully configured Spark in your Windows environment. Have fun with Spark 3.0.0.