This post summarizes the steps to install Zeppelin 0.7.3 in Windows environment.
Tools and Environment
- GIT Bash
- Command Prompt
- Windows 10
Download Binary Package
Download the latest binary package from the following website:
http://zeppelin.apache.org/download.html
In my case, I am saving the file to folder: F:\DataAnalytics
UnZip Binary Package
Open Git Bash, and change directory (cd) to the folder where you save the binary package and then unzip:
$ cd F:\DataAnalytics
fahao@Raymond-Alienware MINGW64 /f/DataAnalytics $ tar -xvzf zeppelin-0.7.3-bin-all.gz
After running the above commands, the package is unzip to folder: F:\DataAnalytics\zeppelin-0.7.3-bin-all
Run Zeppelin
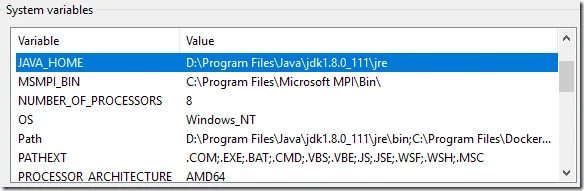
Before starting Zeppelin, make sure JAVA_HOME environment variable is set.
JAVA\_HOME environment variable
JAVA_HOME environment variable value should be your Java JRE path.
Start Zeppelin
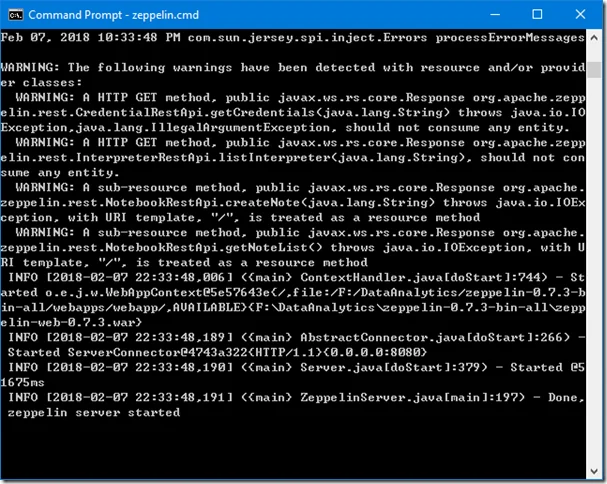
Run the following command in Command Prompt (Remember to the path to your own Zeppelin folder):
cd /D F:\DataAnalytics\zeppelin-0.7.3-bin-all\bin
F:\DataAnalytics\zeppelin-0.7.3-bin-all\bin>zeppelin.cmd
Wait until Zeppelin server is started:
Verify
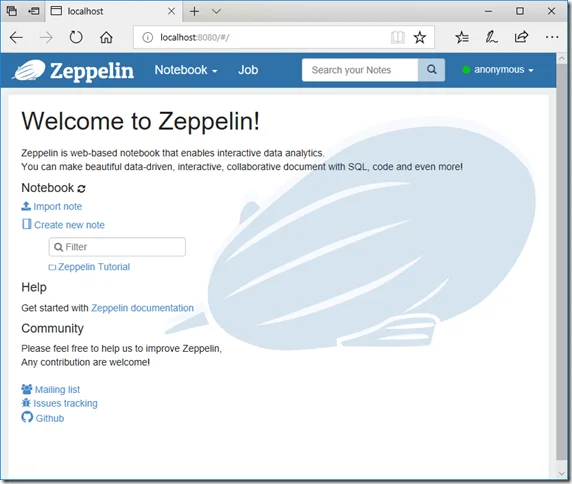
In any of your browser, navigate to http://localhost:8080/
The UI should looks like the following screenshot:
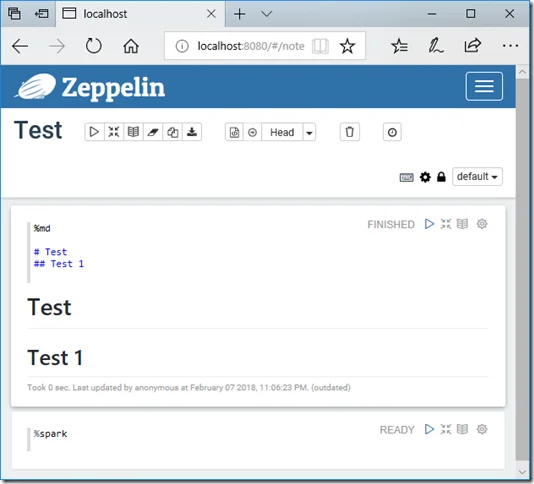
Create Notebook
Create a simple note using markdown and then run it:
java.lang.NullPointerException
If you got this error when using Spark as interpreter, please refer to the following pages for details:
https://issues.apache.org/jira/browse/ZEPPELIN-2438
https://issues.apache.org/jira/browse/ZEPPELIN-2475
Basically, even you configure Spark interpreter not to use Hive, Zeppelin is still trying to locate winutil.exe through environment variableHADOOP_HOME.
Thus to resolve the problem, you need to install Hadoop in your local system and then add one environment variable:
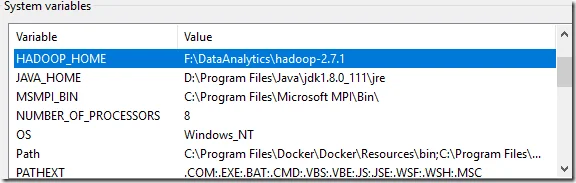
After the environment variable is added, please restart the whole Zeppelin server and then you should be able to run Spark successfully.
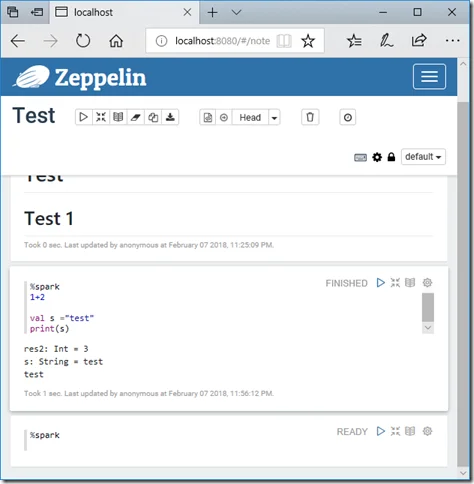
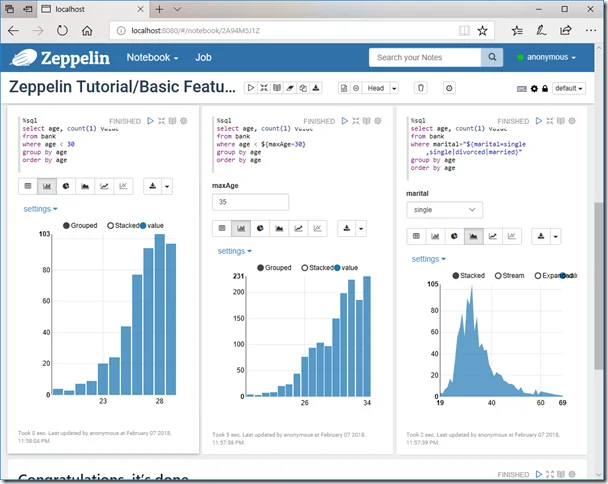
You should also be able to run the tutorials provided as part of the installation:
org.apache.zeppelin.interpreter.InterpreterException:
If you encounter the following error:
org.apache.zeppelin.interpreter.InterpreterException: The filename, directory name, or volume label syntax is incorrect.
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterManagedProcess.start(RemoteInterpreterManagedProcess.java:143) at org.apache.zeppelin.interpreter.remote.RemoteInterpreterProcess.reference(RemoteInterpreterProcess.java:73) at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.open(RemoteInterpreter.java:265) at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.getFormType(RemoteInterpreter.java:430) at org.apache.zeppelin.interpreter.LazyOpenInterpreter.getFormType(LazyOpenInterpreter.java:111) at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:387) at org.apache.zeppelin.scheduler.Job.run(Job.java:175) at org.apache.zeppelin.scheduler.RemoteScheduler$JobRunner.run(RemoteScheduler.java:329) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
It is probably caused by the same issue in this JIRA task if you have installed Spark locally:
https://issues.apache.org/jira/browse/ZEPPELIN-2677
To fix it, you can remove ‘SPARK_HOME’ environment variable and your Spark should still be able to run correctly if you run spark shell using full path of spark-shell.cmd.