Background
This page provides an example to load text file from HDFS through SparkContext in Zeppelin (sc).
Reference
The details about this method can be found at:
SparkContext.textFile
SqlContext
https://spark.apache.org/docs/2.2.1/api/java/org/apache/spark/sql/SQLContext.html
Prerequisites
Hadoop and Zeppelin
Refer to the following page to install Zeppelin and Hadoop in your environment if you don’t have one to play with.
Install Big Data Tools (Spark, Zeppelin, Hadoop) in Windows for Learning and Practice
Sample text file
In this example, I am going to use the file created in this tutorial:
Step by step guide
Create a new note
Create a new note in Zeppelin with Note Name as ‘Test HDFS’:
Create data frame using RDD.toDF function
%spark import spark.implicits._
// Read file as RDD val rdd=sc.textFile("hdfs://0.0.0.0:19000/Sales.csv")
// Convert rdd to dataframe using toDF val df = rdd.toDF z.show(df)
The output:
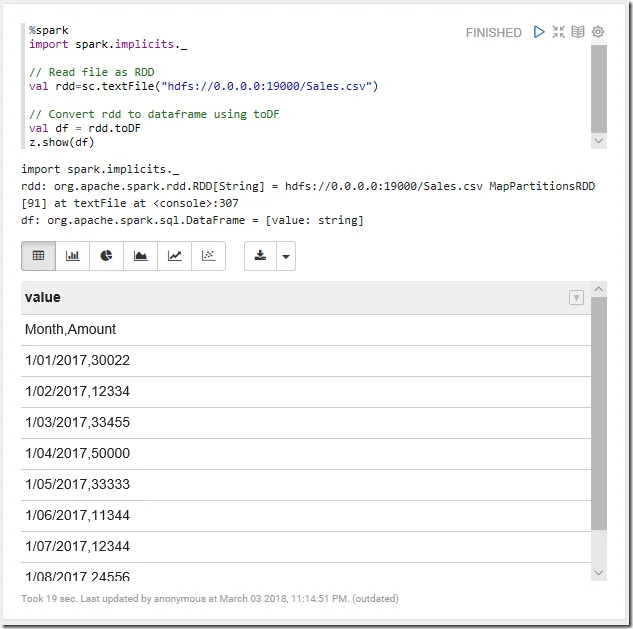
As shown in the above screenshot, each line is converted to one row.
Let’s convert the string rows to string tuples.
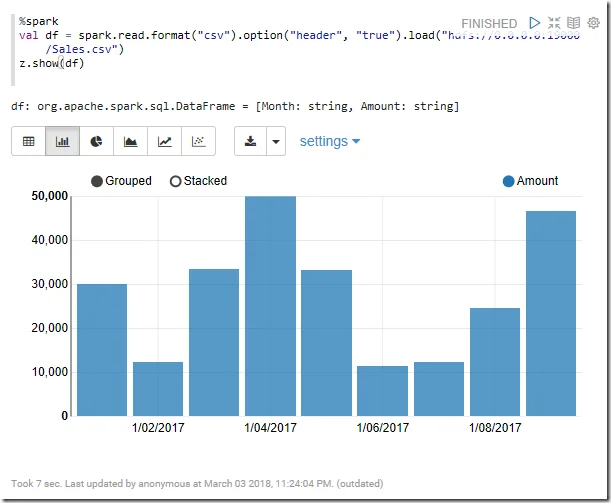
Read CSV using spark.read
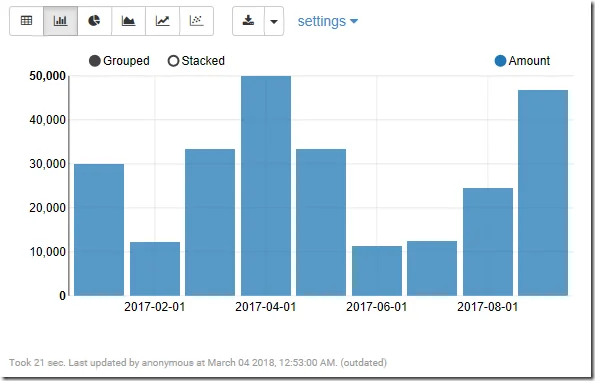
%spark val df = spark.read.format("csv").option("header", "true").load("hdfs://0.0.0.0:19000/Sales.csv") z.show(df)
Alternative method for converting RDD<String> to DataFrame
For previous Spark versions, you may need to convert RDD<String> to DataFrame using map functions.
%spark import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.SQLContext //import spark.implicits._ import java.text.SimpleDateFormat import java.util.Date
// Read file as RDD val rdd=sc.textFile("hdfs://0.0.0.0:19000/Sales.csv") val header = rdd.first() val records = rdd.filter(row => row != header)
// create a data row def row(line: List[String]): Row = { Row(line(0), line(1).toDouble) }
def dfSchema(columnNames: List[String]): StructType = { StructType( Seq(StructField("MonthOld", StringType, true), StructField("Amount", DoubleType, false)) ) } val headerColumns = header.split(",").to[List] val schema = dfSchema(headerColumns) val data = records.map(_.split(",").to[List]).map(row)
//val df = spark.createDataFrame(data, schema) //or val df = new SQLContext(sc).createDataFrame(data, schema) val df2 = df.withColumn("Month", from_unixtime(unix_timestamp($"MonthOld","dd/MM/yyyy"),"yyyy-MM-dd")).drop("MonthOld")
z.show(df2)
The result is similar to the previous one except the date format is also converted: