In this article, I’m going to demo how to install Hive 3.0.0 on Windows 10.
warning Alert - Apache Hive is impacted by Log4j vulnerabilities; refer to page Apache Log4j Security Vulnerabilities to find out the fixes.
Prerequisites
Before installation of Apache Hive, please ensure you have Hadoop available on your Windows environment. We cannot run Hive without Hadoop.
Install Hadoop (mandatory)
I recommend to install Hadoop 3.x to work with Hive 3.0.0.
There are two articles I've published so far and you can follow either of them to install Hadoop:
- Install Hadoop 3.0.0 in Windows (Single Node)
- (Recommended) Install Hadoop 3.2.1 on Windows 10 Step by Step Guide
Hadoop 3.2.1 is recommended as that one provides very detailed steps that are easy to follow.
Tools and Environment
- Windows 10
- Cygwin
- Command Prompt
Install Cygwin
Please install Cygwin so that we can run Linux shell scripts on Windows. From Hive 2.3.0, the binary doesn’t include any CMD file anymore. Thus you have to use Cygwin or any other bash/sh compatible tools to run the scripts.
You can install Cygwin from this site: https://www.cygwin.com/.
Download Binary Package
Download the latest binary from the official website:
Save the downloaded package to a local drive. For my case, I am saving to ‘F:\DataAnalytics’.
If you cannot find the package, you can download from the archive site too: https://archive.apache.org/dist/hive/hive-3.0.0/.
UnZip binary package
Open Cygwin terminal, and change directory (cd) to the folder where you save the binary package and then unzip:
$ cd F:\DataAnalyticsfahao@Raymond-Alienware /cygdrive/f/DataAnalytics $ tar -xvzf apache-hive-3.0.0-bin.tar.gz
Setup environment variables
Run the following commands in Cygwin to setup the environment variables:
export HADOOP_HOME='/cygdrive/f/DataAnalytics/hadoop-3.0.0' export PATH=$PATH:$HADOOP_HOME/bin export HIVE_HOME='/cygdrive/f/DataAnalytics/apache-hive-3.0.0-bin' export PATH=$PATH:$HIVE_HOME/bin export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*.jar
You can add these exports to file .bashrc so that you don’t need to run these command manually each time when you launch Cygwin:
vi ~/.bashrc
* Add the above lines into this file.
Setup Hive HDFS folders
Open Command Prompt (not Cygwin) and then run the following commands:
hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse
Create a symbolic link
As Java doesn’t understand Cygwin path properly, you may encounter errors like the following:
JAR does not exist or is not a normal file: F:\cygdrive\f\DataAnalytics\apache-hive-3.0.0-bin\lib\hive-beeline-3.0.0.jar
In my system, Hive is installed in F:\DataAnalytics\ folder. To make it work, follow these steps:
- Create a folder in F: driver named cygdrive
- Open Command Prompt (Run as Administrator) and then run the following command:
C:\WINDOWS\system32>mklink /J F:\cygdrive\f\ F:\ Junction created for F:\cygdrive\f\ <<===>> F:\
In this way, ‘F:\cygdrive\f’ will be equal to ‘F:\’. You need to change the drive to the appropriate drive where you are installing Hive. For example, if you are installing Hive in C driver, the command line will be:
C:\WINDOWS\system32>mklink /J C:\cygdrive\c\ C:\
Initialize metastore
Now we need to initialize the schemas for metastore.
$HIVE_HOME/bin/schematool -dbType <db type> -initSchema
Type the following command to view all the options:
$HIVE_HOME/bin/schematool -help
For argument dbType, the value can be one of the following databases:
derby|mysql|postgres|oracle|mssql
For this article, I am going to use derby as it is purely Java based and also already built-in with the Hive release:
$HIVE_HOME/bin/schematool -dbType derby -initSchema
The output looks similar to the following:
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting metastore schema initialization to 3.0.0 Initialization script hive-schema-3.0.0.derby.sqlInitialization script completed schemaTool completed
A folder named metastore_db will be created on your current path (pwd).
Configure a remote database as metastore
This step is optional for this article. You can configure it to support multiple sessions.
Please refer to this post about configuring SQL Server database as metastore.
* I would recommend using a remote database as metastore for Hive for proper environment.
Configure API authentication
Add the following configuration into hive-site.xml file.
<property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> <description> Should metastore do authorization against database notification related APIs such as get_next_notification. If set to true, then only the superusers in proxy settings have the permission </description> </property>
Alternatively you can configure proxy user in Hadoop core-site.xml file. Refer to the following post for more details:
HiveServer2 Cannot Connect to Hive Metastore Resolutions/Workarounds
Start HiveServer2 service
Run the following command in Cygwin to start HiveServer2 service:
$HIVE_HOME/bin/hive --service hiveserver2 start
Start HiveServer2 service and run Beeline CLI
Now you can run the following command to start HiveServer2 service and Beeline in the same process:
$HIVE_HOME/bin/beeline -u jdbc:hive2://
Run CLI directly
You can also run the CLI either via hive or beeline command.
$HIVE_HOME/bin/beeline$HIVE_HOME/bin/hive
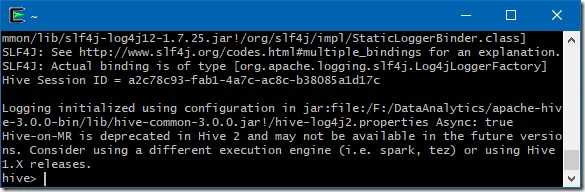
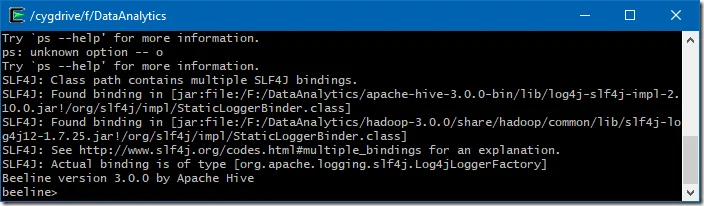
You can also specify beeline commands with JDBC URL of HiveServer2. In the following command, you need to replace $HS2_HOST with HiveServer2 address and $HS2_PORT with HiveServer2 port.
$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT
By default the URL is: jdbc:hive2://localhost:10000.
Until now, we have installed the clients successfully.
DDL practices
Now we have Hive installed successfully, we can run some commands to test.
For more details about the commands, refer to official website:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
Create a new Hive database
Run the following command in Beeline to create a database named test_db:
create database if not exists test_db;
Output of the command looks similar to the following:
0: jdbc:hive2://> create database if not exists test_db; 19/03/26 21:44:09 [HiveServer2-Background-Pool: Thread-115]: WARN metastore.ObjectStore: Failed to get database hive.test_db, returning NoSuchObjectException OK No rows affected (0.312 seconds)
As I didn’t specify the database location, it will be created under the default HDFS location: /user/hive/warehouse.
In HDFS name node, we can see a new folder is created.
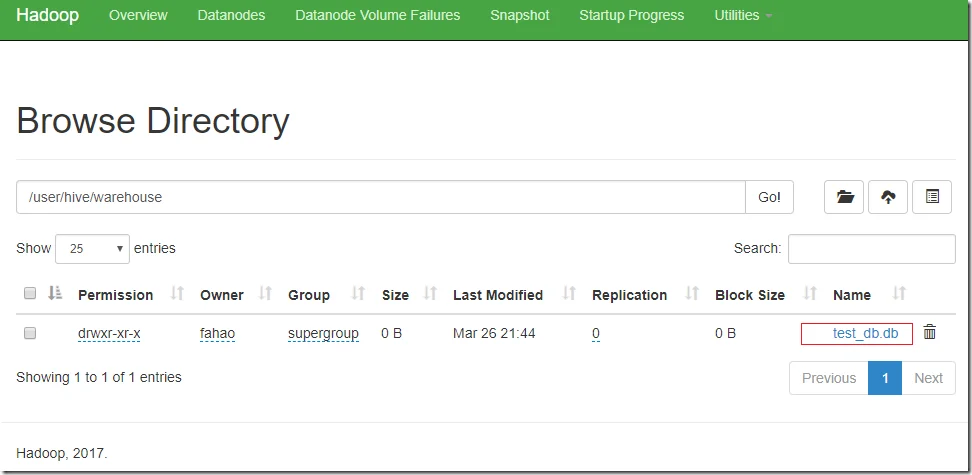
Create a new Hive table
Run the following commands to create a table named test_table:
use test_db; create table test_table (id bigint not null, value varchar(100));show tables;
Insert data into Hive table
Run the following command to insert some sample data:
insert into test_table (id,value) values (1,'ABC'),(2,'DEF');
Two records will be created by the above command.
The command will submit a MapReduce job to YARN. You can also configure Hive to use Spark as execution engine instead of MapReduce.
You can track the job status through Tracking URL printed out by the console output.
Go to YARN, you can also view the job status:
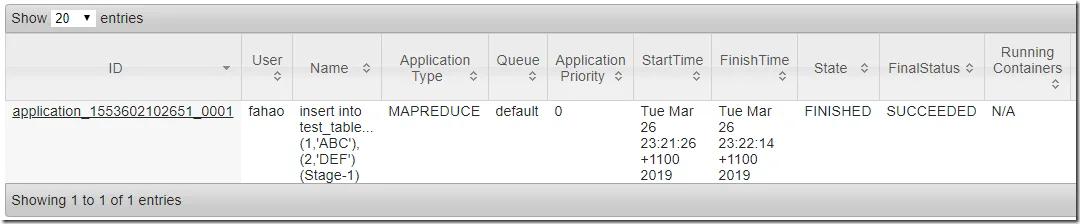
Wait until the job is completed.
Select data from Hive table
Now, you can display the data by running the following command in Beeline:
select * from test_table;
The output looks similar to the following:
0: jdbc:hive2://> select * from test_table; 19/03/26 23:23:18 [93fd08aa-09f6-488a-aa43-28b37d69a504 main]: WARN metastore.ObjectStore: datanucleus.autoStartMechanismMode is set to unsupported value null . Setting it to value: ignored OK +----------------+-------------------+ | test_table.id | test_table.value | +----------------+-------------------+ | 1 | ABC | | 2 | DEF | +----------------+-------------------+ 2 rows selected (0.476 seconds)
In Hadoop NameNode website, you can also find the new files are created:
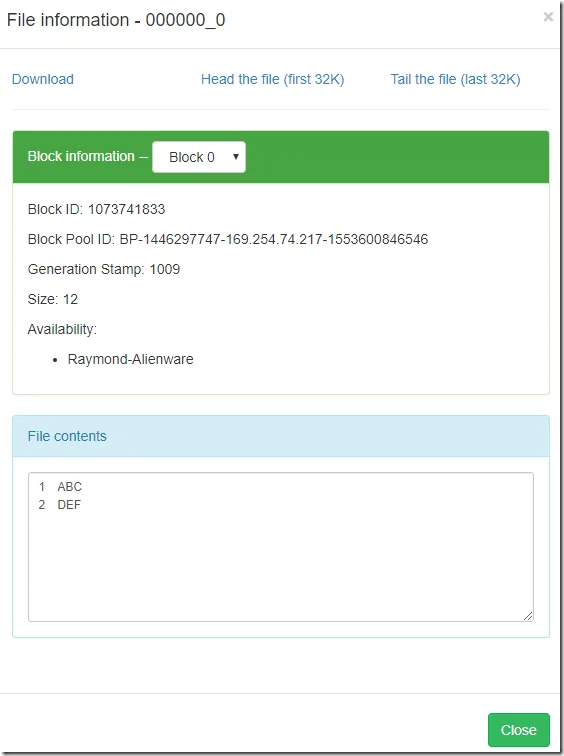
Now you can enjoy working with Hive on Windows!
Fix some errors
hadoop-3.0.0/bin/hadoop: line 2: $'\r': command not found
I got this error in my environment because end line is in Windows format instead of UNIX.
/cygdrive/f/DataAnalytics/apache-hive-3.1.1-bin $ $HIVE_HOME/bin/beeline F:\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 2: $'\r': command not found F:\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 17: $'\r': command not found F:\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 20: $'\r': command not found F:\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 26: syntax error near unexpected token `$'{\r'' ':\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 26: `{ Unable to determine Hadoop version information. 'hadoop version' returned: F:\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 2: $'\r': command not found F:\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 17: $'\r': command not found F:\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 20: $'\r': command not found F:\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 26: syntax error near unexpected token `$'{\r'' ':\DataAnalytics\hadoop-3.0.0/bin/hadoop: line 26: `{
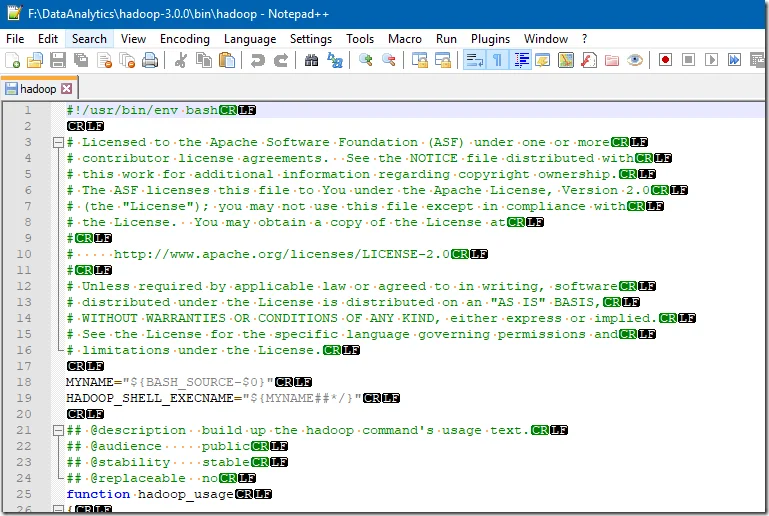
This can be confirmed by opening the hadoop file in Notepad++.
To fix this, click Edit -> EOL Conversion -> Unix (LF).
Do the same for all the other shell scripts if similar errors occur.
I applied the same fix to my following scripts in folder $HADOOP_HOME/bin:
- hdfs
- mapred
- yarn
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
If you use Hadoop 3.2.1 and Hive 3.0.0, you may encounter this error because guava versions are different.
Follow this link to fix it: Hive: Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V.
Other issues
If you encounter any other issues, feel free to post a comment here. I will try to help as much as I can. Before you ask a question, please ensure you exactly followed all the above steps.