This pages summarizes the steps to install the latest version 2.4.3 of Apache Spark on Windows 10 via Windows Subsystem for Linux (WSL).
Prerequisites
Follow either of the following pages to install WSL in a system or non-system drive on your Windows 10.
- Install Windows Subsystem for Linux on a Non-System Drive
- Install Hadoop 3.2.0 on Windows 10 using Windows Subsystem for Linux (WSL)
I also recommend you to install Hadoop 3.2.0 on your WSL following the second page.
After the above installation, your WSL should already have OpenJDK 1.8 installed.
Now let’s start to install Apache Spark 2.4.3 in WSL.
Download binary package
Visit Downloads page on Spark website to find the download URL.

For me, the closest location is: http://apache.mirror.serversaustralia.com.au/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz.
Download the binary package using the following command:
wget http://apache.mirror.serversaustralia.com.au/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
Unzip the binary package
Unpack the package using the following command:
tar -xvzf spark-2.4.3-bin-hadoop2.7.tgz -C ~/hadoop
Setup environment variables
Setup SPARK_HOME environment variables and also add the bin subfolder into PATH variable.
Run the following command to change .bashrc file:
vi ~/.bashrc
Add the following lines to the end of the file:
export SPARK_HOME=~/hadoop/spark-2.4.3-bin-hadoop2.7 export PATH=$SPARK_HOME/bin:$PATHSource the modified file to make it effective:source ~/.bashrc
Now we have setup Spark correctly.
Let’s do some testings.
Run Spark interactive shell
Run the following command to start Spark shell:
spark-shell
The interface looks like the following screenshot:
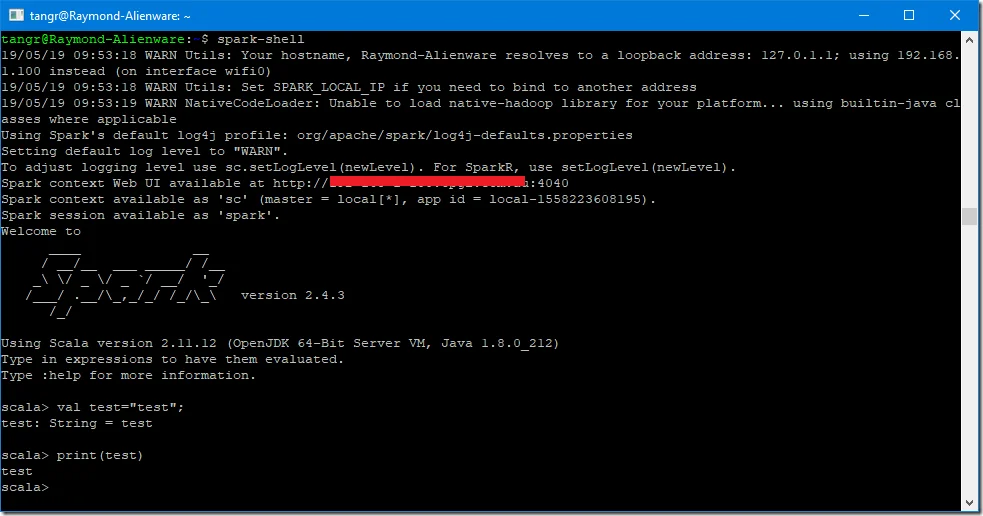
The master is set as local[*].
Run built-in examples
Run Spark Pi example via the following command:
run-example SparkPi 10
In this website, I’ve provided many Spark examples. You can practice following those guides.
Enable Hive support
If you’ve configured Hive in WSL, follow the steps below to enable Hive support in Spark.
Copy the Hadoop core-site.xml and hdfs-site.xml and Hive hive-site.xml configuration files into Spark configuration folder:
cp $HADOOP_HOME/etc/hadoop/core-site.xml $SPARK_HOME/conf/cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $SPARK_HOME/conf/cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf/
And then you can run Spark with Hive support (enableHiveSupport function):
from pyspark.sql import SparkSessionappName = "PySpark Hive Example" master = "local[*]" spark = SparkSession.builder \ .appName(appName) \ .master(master) \ .enableHiveSupport() \ .getOrCreate()# Read data using Spark df = spark.sql("show databases") df.show()
For more details, please refer to this page: Read Data from Hive in Spark 1.x and 2.x.
Spark default configurations
Run the following command to create a spark default config file using the template:
cp spark-defaults.conf.template spark-defaults.conf
Update the config file with default Spark configurations. These configurations will be added when Spark jobs are submitted.
In my following configuration, I added event log directory and also Spark history log directory.
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# Default system properties included when running spark-submit.
# This is useful for setting default environmental settings.
# Example:
# spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:19000/spark-event-logs
spark.history.fs.logDirectory hdfs://localhost:19000/spark-event-logs
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
Spark history server
Run the following command to start Spark history server:
$SPARK_HOME/sbin/start-history-server.sh
Open the history server UI (by default: http://localhost:18080/) in browser, you should be able to view all the jobs submitted.

spark.eventLog.dir and spark.history.fs.logDirectory
These two configurations can be the same or different. The first configuration is used to write event logs when Spark application runs while the second directory is used by the historical server to read event logs.
Have fun with Spark in WSL!