Traditionally Slowly Changing Dimension (SCD) type 2 tables are implemented to save both current and historical data overtime in a data warehouse. It provides flexibility to query both as-is and as-was data with minimized storage requirement. It was very cost efficient when computing and storage were expensive.
What is SCD type 2
SCD type 2 is one of the methodologies to keep both current and historical data for a table with slowly changing records in a dimensional data warehouse. One of the typical example dimension is Customer dimension:
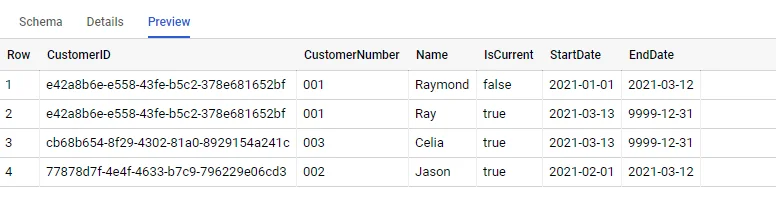
The above screenshot shows customer 001 changed name from Raymond to Ray on 2021-03-13. StartDateand EndDatecolumns can be used to support as-is and as-was queries.
Drawbacks of SCD 2 table
With the cheap storage and computing resources provided by on-premise big data platforms or public cloud platforms, storage cost and computing become less important. The speed of delivery is one of the most important factor to measure the success of a data warehousing project.
The drawbacks of SCD type 2 methodology includes:
- Not easy to implement on big data platform or cloud data warehousing environments as most of them are not designed or optimized for UPDATES.
- Difficult to reload if there were errors. It usually involves a historical merge scenario that is one of the most complex thing to deal with for a data engineer.
Google Cloud BigQuery does support MERGE statement which can be used to implement SCD Type 2 dimensions. Refer to my previous article MERGE Statement in BigQuery for more details.
This article provides another approach - insert only virtualized SCD Type 2 methodology. This is inspired from Data Vault 2.0 INSERT-ONLY satellites. For those not familiar with Data vault modelling method, refer to this wiki page Data vault modeling.
Implement virtualized SCD type 2 dimension
Scenario
Let's assume that each day there is one extract of delta records for customers.
infolf the extract is FULL (i.e. including all the current records), you could just implement a daily snapshot table or find out deltas when loading each file and only save delta records. This article only focuses on implementing SCD type 2 with delta extracts directly.
The following are some sample data that will be used in the following sections:
File 2021-10-01.csv
CustomerNo, Name, DeltaType
"001", "Raymond", 0
"002", "Rob", 0
'003', "Fiona", 0
File 2021-10-02.csv
CustomerNo, Name, DeltaType"001", "Ray", 1
File 2021-10-03.csv
CustomerNo, Name, DeltaType"003", "Fiona", 2
"004", "Kelly", 0
DeltaTypefield indicates the delta types:
- 0 - New records
- 1 - Update records
- 2 - Delete records
Thus, these three sample files can be interpreted as:
- On 2021-10-01, three new customers are created.
- On 2021-10-02, customer 001 changes name to Ray from Raymond.
- On 2021-10-03, customer 003 named Fiona is deleted from source and a new customer named Kelly is added.
Solution overview
We can use BigQuery date partitioned table to load each business day's customer data into BigQuery. To enable easy joins between tables (especially for tables with composite business keys), we can create hash values from business keys (CustomerNoattribute for this scenario). And then we can create a view on top of the partitioned staging table using windowing function. This view will look like a typical SCD Type 2 table. Since it is a view without materialization, I am calling it a 'virtual SCD type 2 table'.
Load data
To learn about how to load CSV files into BigQuery, refer to my previous article Load CSV File from Google Cloud Storage to BigQuery Using Dataflow. To save time, we will just directly create a partitioned table and then insert data into it using the following standard SQL scripts:
1) Create table
This table is created without partition expiry clause. It is important as the source data is provided in a delta manner. If any partition is expired and deleted, the table will miss data and will not be complete.
CREATE TABLE
test.dim_customer (CustomerID STRING, CustomerNO STRING, Name STRING, BUSINESS_DATE DATE, DeltaType BYTEINT)
PARTITION BY
BUSINESS_DATE;
2) Insert records
After the table is created, use the following scripts to insert records directly:
INSERT INTO `test.dim_customer` values(TO_HEX(MD5('001')),'001','Raymond', DATE'2021-10-01',0);INSERT INTO `test.dim_customer` values(TO_HEX(MD5('002')),'002','Rob', DATE'2021-10-01',0);INSERT INTO `test.dim_customer` values(TO_HEX(MD5('003')),'003','Fiona', DATE'2021-10-01',0);INSERT INTO `test.dim_customer` values(TO_HEX(MD5('001')),'001','Ray', DATE'2021-10-02',1);INSERT INTO `test.dim_customer` values(TO_HEX(MD5('003')),'003','Fiona', DATE'2021-10-03',2);INSERT INTO `test.dim_customer` values(TO_HEX(MD5('004')),'004','Kelly', DATE'2021-10-03',0);
The table looks like the following screenshot after the insert statements are executed:

Implement virtual view
Now we can create a view to implement the virtual SCD type 2 table. I will discuss details about the query as it self-explains. If you have any question, feel free to add a comment.
The code for view creation:
CREATE OR REPLACE VIEW test.vw_dim_customerASSELECT CustomerID,CustomerNO,Name,CASE WHEN DeltaType = 2 THEN 1 ELSE 0 END AS IsDeleted,BUSINESS_DATE AS StartDate,COALESCE(LEAD(BUSINESS_DATE) OVER (PARTITION BY CustomerID ORDER BY BUSINESS_DATE) - 1, DATE'9999-12-31') AS EndDateFROM `test.dim_customer`;
Query the virtualized SCD 2 table (view)
Run the following query to show all the data in the view:
SELECT * FROM test.vw_dim_customer ORDER BY CustomerNO, StartDate;
The result looks like the following screenshot:

To query the latest data, use this filter: EndDate=DATE'9999-12-31'. You can also use the typical BETWEEN AND clause to query as-was data.
Reflection
There is a drawback of using this approach: it is possible that a query will need to read all partitions data from the underlying table, which can potentially incurs costs when querying the data. Considering the source table is slowly changing, we would expect the total size of the table will not increase too much overtime.
There are also a few approaches to mitigate this. I will discuss about them in other articles. Stay tuned!