This post shows how to derive new column in a Spark data frame from a JSON array string column. I am running the code in Spark 2.2.1 though it is compatible with Spark 1.6.0 (with less JSON SQL functions).
Prerequisites
Refer to the following post to install Spark in Windows.
*If you are using Linux or UNIX, the code should also work.
Requirement
Convert the following list to a data frame:
source = [{"attr_1": 1, "attr_2": "[{\"a\":1,\"b\":1},{\"a\":2,\"b\":2}]"}, {"attr_1": 2, "attr_2": "[{\"a\":3,\"b\":3},{\"a\":4,\"b\":4}]"}]
The data frame should have two column:
- attr_1: column type is IntegerType
- attr_2: column type is ArrayType (element type is StructType with two StructField).
And the schema of the data frame should look like the following:
root |-- attr_1: long (nullable = true) |-- attr_2: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- a: integer (nullable = false) | | |-- b: integer (nullable = false)
Resolution
Convert list to data frame
First, let’s convert the list to a data frame in Spark by using the following code:
# Read the list into data framedf = sqlContext.read.json(sc.parallelize(source))df.show()df.printSchema()
JSON is read into a data frame through sqlContext. The output is:
+------+--------------------+ |attr_1| attr_2| +------+--------------------+ | 1|[{"a":1,"b":1},{"...| | 2|[{"a":3,"b":3},{"...| +------+--------------------+
root |-- attr_1: long (nullable = true) |-- attr_2: string (nullable = true)
At current stage, column attr_2 is string type instead of array of struct.
Create a function to parse JSON to list
For column attr_2, the value is JSON array string. Let’s create a function to parse JSON string and then convert it to list.
# Function to convert JSON array string to a listimport jsondef parse_json(array_str):json_obj = json.loads(array_str)for item in json_obj: yield (item["a"], item["b"])
Define the schema of column attr\_2
# Define the schemafrom pyspark.sql.types import ArrayType, IntegerType, StructType, StructFieldjson_schema = ArrayType(StructType([StructField('a', IntegerType(), nullable=False), StructField('b', IntegerType(), nullable=False)]))
Based on the JSON string, the schema is defined as an array of struct with two fields.
Create an UDF
Now, we can create an UDF with function parse_json and schemajson_schema.
# Define udffrom pyspark.sql.functions import udfudf_parse_json = udf(lambda str: parse_json(str), json_schema)
Create a new data frame
Finally, we can create a new data frame using the defined UDF.
# Generate a new data frame with the expected schemadf_new = df.select(df.attr_1, udf_parse_json(df.attr_2).alias("attr_2"))df_new.show()df_new.printSchema()
The output is as the following:
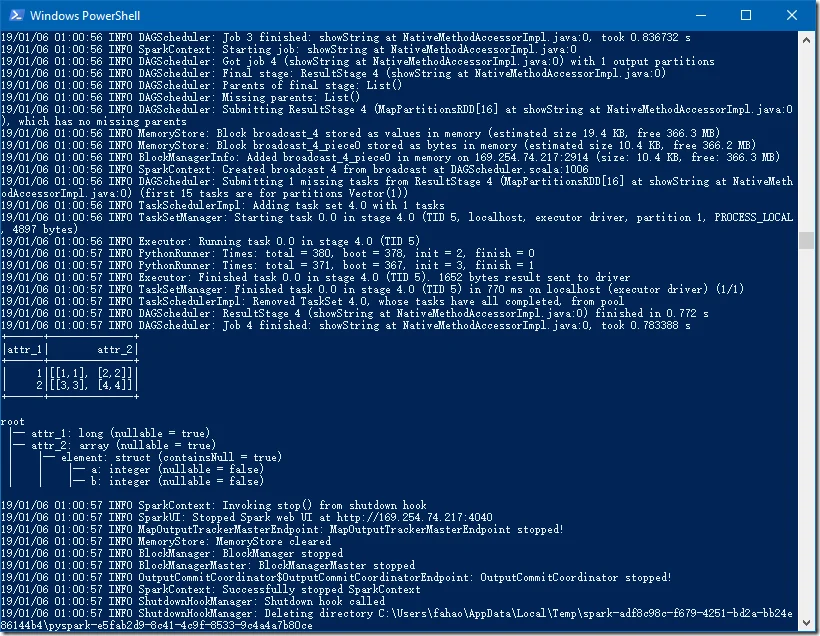
+------+--------------+ |attr_1| attr_2| +------+--------------+ | 1|[[1,1], [2,2]]| | 2|[[3,3], [4,4]]| +------+--------------+
root |-- attr_1: long (nullable = true) |-- attr_2: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- a: integer (nullable = false) | | |-- b: integer (nullable = false)
Summary
The following is the complete code:
from pyspark import SparkContext, SparkConf, SQLContextappName = "JSON Parse Example"master = "local[2]"conf = SparkConf().setAppName(appName).setMaster(master)sc = SparkContext(conf=conf)sqlContext = SQLContext(sc)source = [{"attr_1": 1, "attr_2": "[{\"a\":1,\"b\":1},{\"a\":2,\"b\":2}]"}, {"attr_1": 2, "attr_2": "[{\"a\":3,\"b\":3},{\"a\":4,\"b\":4}]"}]# Read the list into data framedf = sqlContext.read.json(sc.parallelize(source))df.show()df.printSchema()# Function to convert JSON array string to a listimport jsondef parse_json(array_str):json_obj = json.loads(array_str)for item in json_obj:yield (item["a"], item["b"])# Define the schemafrom pyspark.sql.types import ArrayType, IntegerType, StructType, StructFieldjson_schema = ArrayType(StructType([StructField('a', IntegerType(), nullable=False), StructField('b', IntegerType(), nullable=False)]))# Define udffrom pyspark.sql.functions import udfudf_parse_json = udf(lambda str: parse_json(str), json_schema)# Generate a new data frame with the expected schemadf_new = df.select(df.attr_1, udf_parse_json(df.attr_2).alias("attr_2"))df_new.show()df_new.printSchema()
Save the code as file parse_json.py and then you can use the following command to run it in Spark:
spark-submit parse_json.py
The following screenshot is captured from my local environment (Spark 2.2.1 & Python 3.6.4 in Windows ).