DuckDB azure extension has not fully implemented with writing files like Parquet into Azure Blob Storage container. You can use it to query data in storage account though.
For simplicity, I will use Azurite (local Azure blob storage emulator) to show you how to setup DuckLake with Azure.
Create a Python virtual environment
Create a Python virtual environment with your favorite tool (pip, conda, uv, poetry, etc.).
python -m venv .venv
Then activate the environment.
Install dependencies
Install the following dependencies that will be requried.
pip install duckdb pandas fsspec adlfs
Query with azure extension
Now we can use SQL to read data from Azure Blob Storage. We need to install ducklake (not required for this step but for later steps) and azure extension.
For local emulator, the following are the details:
- AZURE_CONNECTION_STRING: "DefaultEndpointsProtocol=http;AccountName=devstoreaccount1;AccountKey=Eby8vdM02xNOcqFlqUwJPLlmEtlCDXJ1OUzFT50uSRZ6IFsuFq2UVErCz4I6tq/K1SZFPTOtr/KBHBeksoGMGw==;BlobEndpoint=http://127.0.0.1:10000/devstoreaccount1;"
- AZURE_STORAGE_ACCOUNT_NAME = "devstoreaccount1"
- AZURE_CONTAINER_NAME = "data-lake"
- PARQUET_FILE_PATH_IN_CONTAINER = "weather.parquet"
I am using a sample weather parquet file and you can use any file types that are supported by DuckDB. If your Azurite is running on different port, please change the connection string accordingly.
import duckdb
from fsspec import filesystem
def main():
# Connect to an in-memory DuckDB database
# To connect to a file-based database, replace ':memory:' with a file path, e.g., 'my_database.duckdb'
con = duckdb.connect(database=':memory:', read_only=False)
print("Successfully connected to in-memory DuckDB.")
# Install ducklake and azure extensions
try:
con.execute("INSTALL 'ducklake';")
con.execute("LOAD 'ducklake';")
con.execute("INSTALL 'azure';")
con.execute("LOAD 'azure';")
print("Extensions installed successfully.")
except Exception as e:
print(f"Error installing extensions: {e}")
AZURE_CONNECTION_STRING = "DefaultEndpointsProtocol=http;AccountName=devstoreaccount1;AccountKey=Eby8vdM02xNOcqFlqUwJPLlmEtlCDXJ1OUzFT50uSRZ6IFsuFq2UVErCz4I6tq/K1SZFPTOtr/KBHBeksoGMGw==;BlobEndpoint=http://127.0.0.1:10000/devstoreaccount1;"
AZURE_STORAGE_ACCOUNT_NAME = "devstoreaccount1"
AZURE_CONTAINER_NAME = "data-lake"
PARQUET_FILE_PATH_IN_CONTAINER = "weather.parquet"
# Create azurite secret store
# secret_scope = f"az://{AZURE_STORAGE_ACCOUNT_NAME}/"
secret_scope = f"az://{AZURE_CONTAINER_NAME}/"
con.execute(f"""
CREATE SECRET IF NOT EXISTS azurite_read_secret (
TYPE AZURE,
CONNECTION_STRING '{AZURE_CONNECTION_STRING}',
SCOPE '{secret_scope}'
);
""")
print("Azurite secret created.")
# Full URI to the Parquet file
# For Azurite, the account name is 'devstoreaccount1'.
# For real Azure, it's your actual storage account name.
# PARQUET_URI = f"az://{AZURE_STORAGE_ACCOUNT_NAME}/{AZURE_CONTAINER_NAME}/{PARQUET_FILE_PATH_IN_CONTAINER}"
PARQUET_URI = f"az://{AZURE_CONTAINER_NAME}/{PARQUET_FILE_PATH_IN_CONTAINER}"
print(f"\nAttempting to query Parquet file from: {PARQUET_URI}")
query = f"""
SELECT
*
FROM
'{PARQUET_URI}' AS weather
LIMIT 5;
"""
result_df = con.execute(query).fetchdf()
print("\nQuery results (first 5 rows):")
print(result_df)
con.close()
if __name__ == "__main__":
main()
The above scripts install two extensions and register secret about connection strings to connect to blob storage account. Running the script will print out results like the following:
Successfully connected to in-memory DuckDB.
Extensions installed successfully.
Azurite secret created.
Attempting to query Parquet file from: az://data-lake/weather.parquet
Query results (first 5 rows):
MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustDir ... Cloud3pm Temp9am Temp3pm RainToday RISK_MM RainTomorrow
0 8.0 24.3 0.0 3.4 6.3 NW ... 7 14.4 23.6 No 3.6 Yes
[5 rows x 22 columns]
Create DuckLake
As mentioned earlier, azure extension currently doesn't support writing into blob storage container.
We will use the packages fsspec and adlfs. Without these two packages, you may encounter the following errors:
- Not implemented Error: Writing to Azure containers is currently not supported
- ImportError: Install adlfs to access Azure Datalake Gen2 and Azure Blob Storage
Now let's add the code to create a DuckLake with data stored in Azure Blob Storage container.
# Now create a ducklake
try:
# The DATA_PATH specifies where the table data will be stored in Azure Blob Storage
con.execute(f"ATTACH 'ducklake:metadata.ducklake' AS my_ducklake (DATA_PATH 'abfs://{AZURE_CONTAINER_NAME}/lake/');")
print(f"Ducklake 'my_ducklake' attached successfully. Table data will be stored in abfs://{AZURE_CONTAINER_NAME}/lake/")
except Exception as e:
print(f"Error attaching Ducklake: {e}")
con.close()
return
# Create a table within the DuckLake
try:
con.execute("""
CREATE TABLE IF NOT EXISTS my_ducklake.my_table (
id INTEGER,
name STRING
);
""")
print("Table 'my_ducklake.my_table' created successfully or already exists.")
except Exception as e:
print(f"Error creating table 'my_ducklake.my_table': {e}")
con.close()
return
# Insert data into the DuckLake table
try:
con.execute("INSERT INTO my_ducklake.my_table VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Carol')")
print("Data inserted into 'my_ducklake.my_table' successfully.")
except Exception as e:
# It's possible data was already inserted if run multiple times,
# for a real application, consider UPSERT or checking existence.
print(f"Error inserting data into 'my_ducklake.my_table' (or data might already exist): {e}")
# Query the DuckLake table
try:
lake_table_result = con.execute("SELECT * FROM my_ducklake.my_table").fetchall()
print("\nQuery results from 'my_ducklake.my_table':")
for row in lake_table_result:
print(row)
except Exception as e:
print(f"Error querying 'my_ducklake.my_table': {e}")
Running the above scripts will print out the following output:
Ducklake 'my_ducklake' attached successfully. Table data will be stored in abfs://data-lake/lake/
Table 'my_ducklake.my_table' created successfully or already exists.
Data inserted into 'my_ducklake.my_table' successfully.
Query results from 'my_ducklake.my_table':
(1, 'Alice')
(2, 'Bob')
(3, 'Carol')
(1, 'Alice')
(2, 'Bob')
(3, 'Carol')
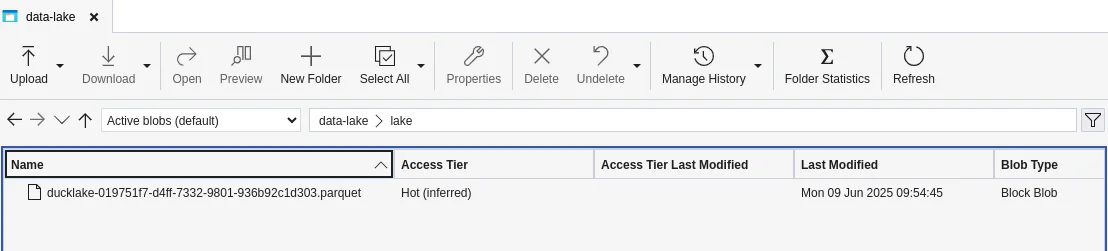
Examine the blob storage container, you will notice parquet files created.
About metadata
For this example, the metadata is stored in DuckDB in memory database. Once the connection is gone, the metadata will be gone and you won't be able to query DuckLake parquet files easily though you can get the RAW data stored in each files.
References
- https://ducklake.select/docs/stable/duckdb/usage/choosing_storage
- https://ducklake.select/manifesto/
Enjoy your exploration with DuckLake!