When submitting Spark applications to YARN cluster, two deploy modes can be used: client and cluster. For client mode (default), Spark driver runs on the machine that the Spark application was submitted while for cluster mode, the driver runs on a random node in a cluster. On this page, I am going to show you how to submit an PySpark application with multiple Python script files in both modes.
PySpark application
The application is very simple with two scripts file.
pyspark\_example.py
from pyspark.sql import SparkSession
from pyspark_example_module import test_function
appName = "Python Example - PySpark Row List to Pandas Data Frame"
# Create Spark session
spark = SparkSession.builder \
.appName(appName) \
.getOrCreate()
# Call the function
test_function()
This script file references another script file named pyspark_example_module.py. It creates a Spark session and then call the function from the other module.
pyspark\_example\_module.py
This script file is a simple Python script file with a simple function in it.
def test_function():
"""
Test function
"""
print("This is a test function")
Run the application with local master
To run the application with local master, we can simply call spark-submit CLI in the script folder.
spark-submit pyspark_example.py
Run the application in YARN with deployment mode as client
Deploy mode is specified through argument --deploy-mode. --py-files is used to specify other Python script files used in this application.
spark-submit --master yarn --deploy-mode client --py-files pyspark_example_module.py pyspark_example.py
Run the application in YARN with deployment mode as cluster
To run the application in cluster mode, simply change the argument --deploy-mode to cluster.
spark-submit --master yarn --deploy-mode cluster --py-files pyspark_example_module.py pyspark_example.py
The scripts will complete successfully like the following log shows:
2019-08-25 12:07:09,047 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: *** ApplicationMaster RPC port: 3047 queue: default start time: 1566698770726 final status: SUCCEEDED tracking URL: http://localhost:8088/proxy/application_1566698727165_0001/ user: tangr
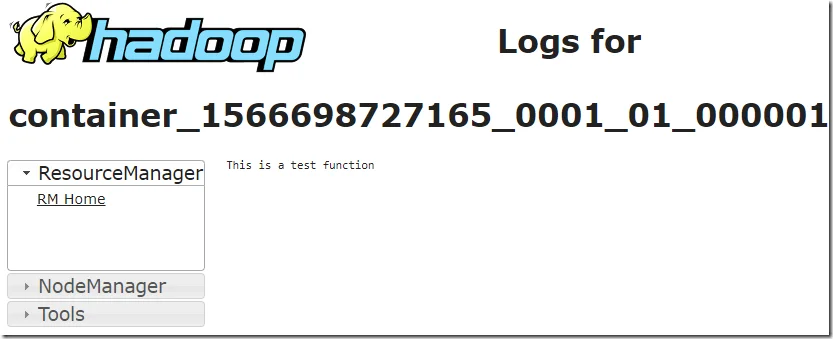
In YARN, the output is shown too as the above screenshot shows.
Submit scripts to HDFS so that it can be accessed by all the workers
When submit the application through Hue Oozie workflow, you usually can use HDFS file locations.
Use the following command to upload the script files to HDFS:
hadoop fs -copyFromLocal *.py /scripts
Both scripts are uploaded to the /scripts folder in HDFS:
-rw-r--r-- 1 tangr supergroup 288 2019-08-25 12:11 /scripts/pyspark_example.py -rw-r--r-- 1 tangr supergroup 91 2019-08-25 12:11 /scripts/pyspark_example_module.py
And then run the following command to use the HDFS scripts:
spark-submit --master yarn --deploy-mode cluster --py-files hdfs://localhost:19000/scripts/pyspark_example_module.py hdfs://localhost:19000/scripts/pyspark_example.py
The application should be able to complete successfully without errors.
If you use Hue, follow this page to set up your Spark action: How to Submit Spark jobs with Spark on YARN and Oozie.
Replace the file names accordingly:
- Jar/py names: pyspark_example.py
- Files: /scripts/pyspark_example_module.py
- Options list: --py-files pyspark_example_module.py. If you have multiple files, sperate them with comma.
- In the settings of this action, change master and deploy mode accordingly.
*Image from gethue.com.