Apache Kylin is an open source analytical data warehouse for Big Data. It supports OLAP workloads with sub-second latency. You can use Kylin to build cubes from identified tables. The official project site is hosted at: Apache Kylin | Analytical Data Warehouse for Big Data. This tutorial provides how to setup a Kylin environment quickly using Docker.
Apache Kylin architecture
The following diagram shows how Apache Kylin works on big data.
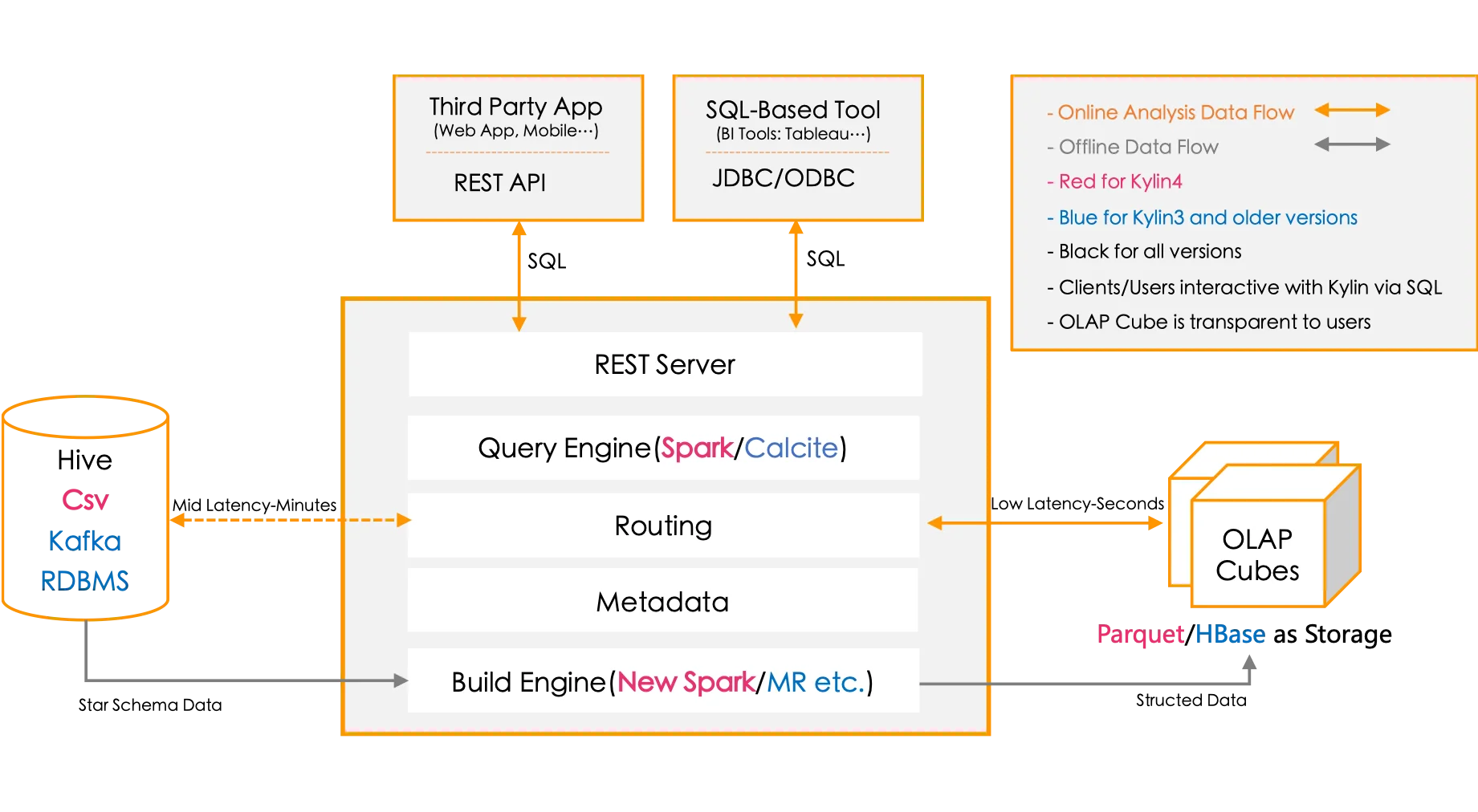 *Image credit - https://kylin.apache.org/assets/images/kylin\_diagram.png
*Image credit - https://kylin.apache.org/assets/images/kylin\_diagram.png
{kind=link}
Prerequisites
Apache Kylin can be configured in your big data cluster as Spark or other frameworks does. To save time and effort, we will use the official docker image. Please install the latest Docker Desktop if it is not available in your system.
If you use WSL 2 in Docker, please ensure sufficient memory is configured in .wslconfig file:
[wsl2]
memory=8GB # Limits VM memory in WSL 2
Pull image
Run the following command to pull the latest image (as at 14/09/2023):
docker pull apachekylin/apache-kylin-standalone:5.0-beta
The above command pulls the latest 5.0.0-beta release. In the image, Hadoop, Hive (incl. metastore database MySQL), Spark and ZooKeeper are also included to support Apache Kylin.
Start the container
Run the following command to start the container: Bash:
docker run -d \
--name Kylin5-Machine \
--hostname Kylin5-Machine \
-m 8G \
-p 7070:7070 \
-p 8088:8088 \
-p 9870:9870 \
-p 8032:8032 \
-p 8042:8042 \
-p 2181:2181 \
apachekylin/apache-kylin-standalone:5.0-beta
PowerShell:
docker run -d `
--name Kylin5-Machine `
--hostname Kylin5-Machine `
-m 8G `
-p 7070:7070 `
-p 8088:8088 `
-p 9870:9870 `
-p 8032:8032 `
-p 8042:8042 `
-p 2181:2181 `
apachekylin/apache-kylin-standalone:5.0-beta
If any port is used by other programs in the host machine, you can change the port mapping to other ports, for example -p 10088:8088. And then run the following command to display the logs:
docker logs --follow Kylin5-Machine
Wait until all services are started. It may take quite a few minutes as it performs the following actions
- MySQL service
- Init Hive schema for metastore
- HDFS format
- HDFS (NameNode and DataNode)
- Hive services
- YARN (ResourceManager and NodeManager)
- Load sample data into HDFS for Kylin and create tables: ssb.customer, ssb.dates, ssb.lineorder, ssb.part, ssb.supplier
- Create sample model
- Start Kylin instance
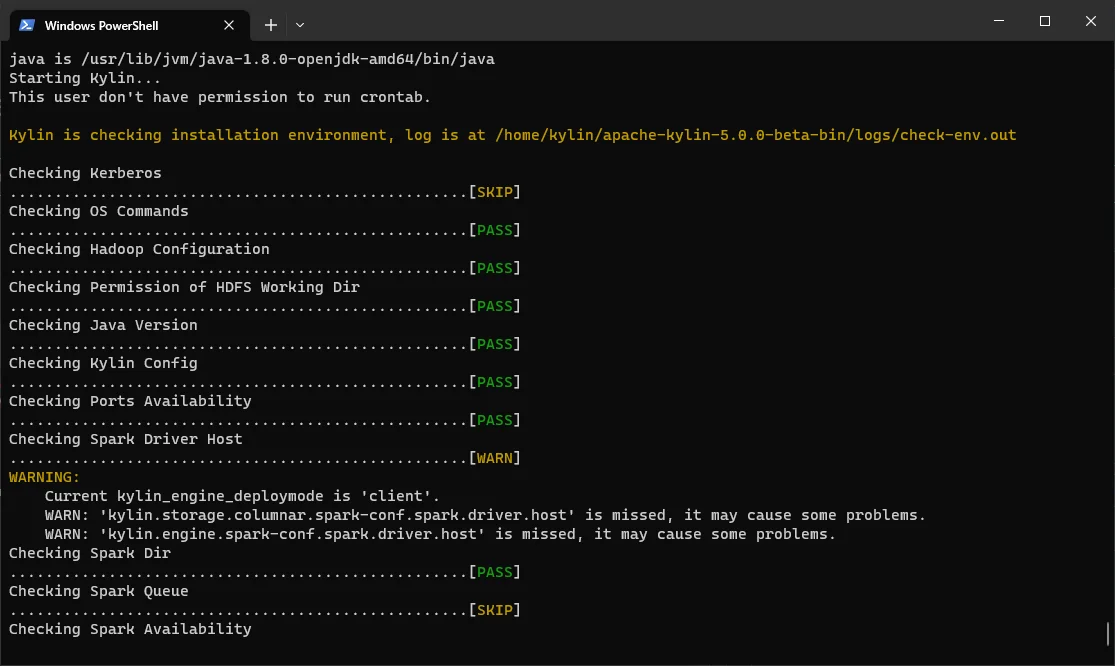 When all services are started, you should be able to see the following log:
When all services are started, you should be able to see the following log:
Kylin service is already available for you to preview.
Services in the container
The following services are available:
| Service Name | URL |
|---|---|
| Kylin | http://localhost:7070/kylin |
| Yarn | http://localhost:8088 |
| HDFS | http://localhost:9870 |
If you cannot open Kylin web UI, the service might not started successfully. You can try run the following command in the container's terminal:
${KYLIN_HOME}/bin/kylin.sh start
Sometimes you may need to wait for a while before the web service is up.
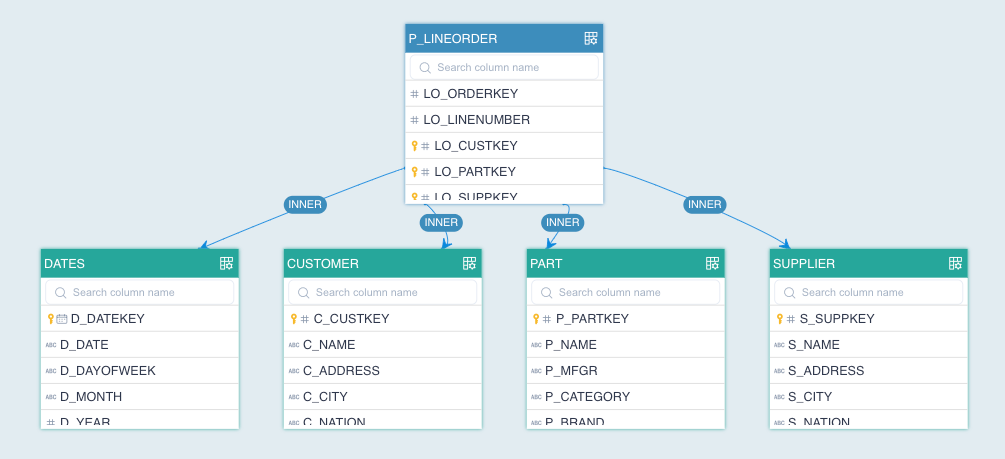
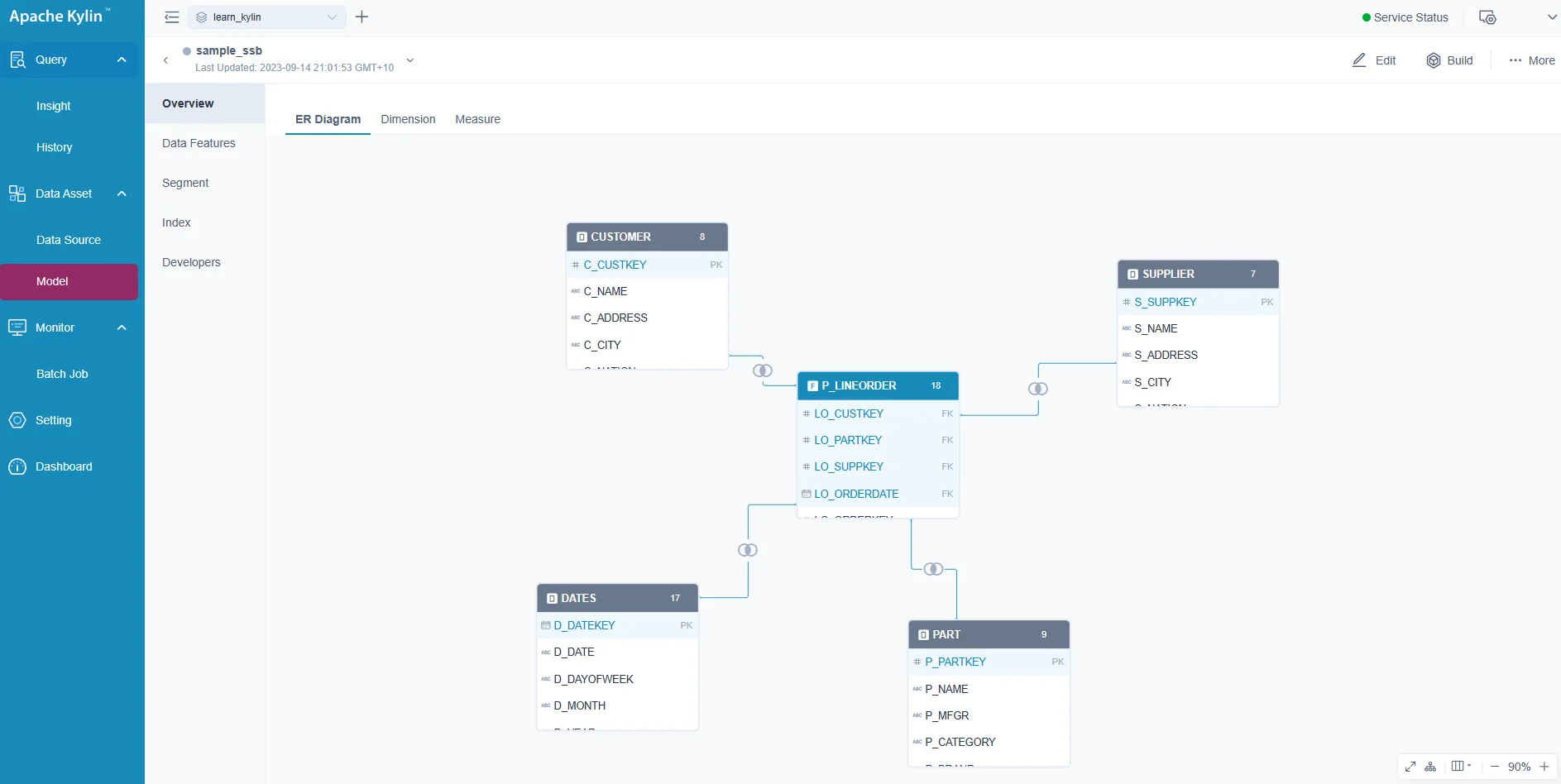
About the sample data model
The sample data model is a star-schema as the following screenshot shows:
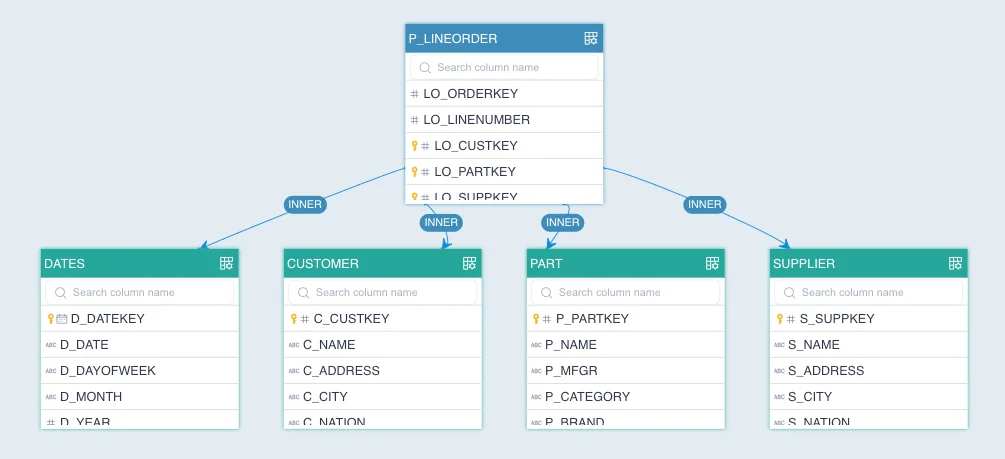 *Image credit: https://kylin.apache.org/5.0/assets/images/dataset-d22cdf576e3d87e0f1a2b4531b6a5d60.png
The fact table is linked to the dimensional tables. For more information about the sample dataset, please refer to Sample dataset | Welcome to Kylin 5 (apache.org).
*Image credit: https://kylin.apache.org/5.0/assets/images/dataset-d22cdf576e3d87e0f1a2b4531b6a5d60.png
The fact table is linked to the dimensional tables. For more information about the sample dataset, please refer to Sample dataset | Welcome to Kylin 5 (apache.org).
{kind=link}
Explore Kylin UI
Open http://localhost:7070/kylin in a browser, we can explore the UI of Kylin. Please login with the following credential:
- username: ADMIN
- password: KYLIN
 The UI provides pages to create projects, add data sources and design models and indexes, load data (load data from source, build indexes and pre-calculation), query data using ANSI SQL, monitor jobs, etc.
The UI provides pages to create projects, add data sources and design models and indexes, load data (load data from source, build indexes and pre-calculation), query data using ANSI SQL, monitor jobs, etc.
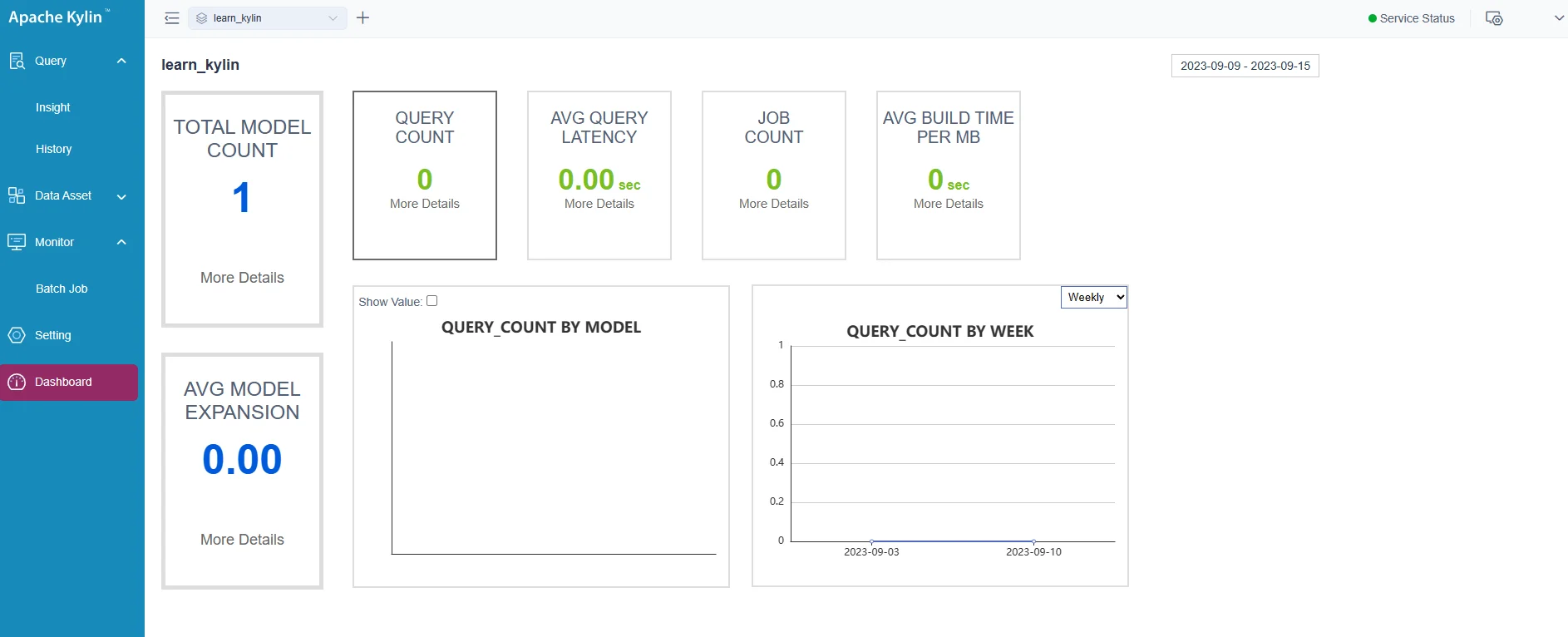
Dashboard
The following screenshot shows the dashboard about stats.
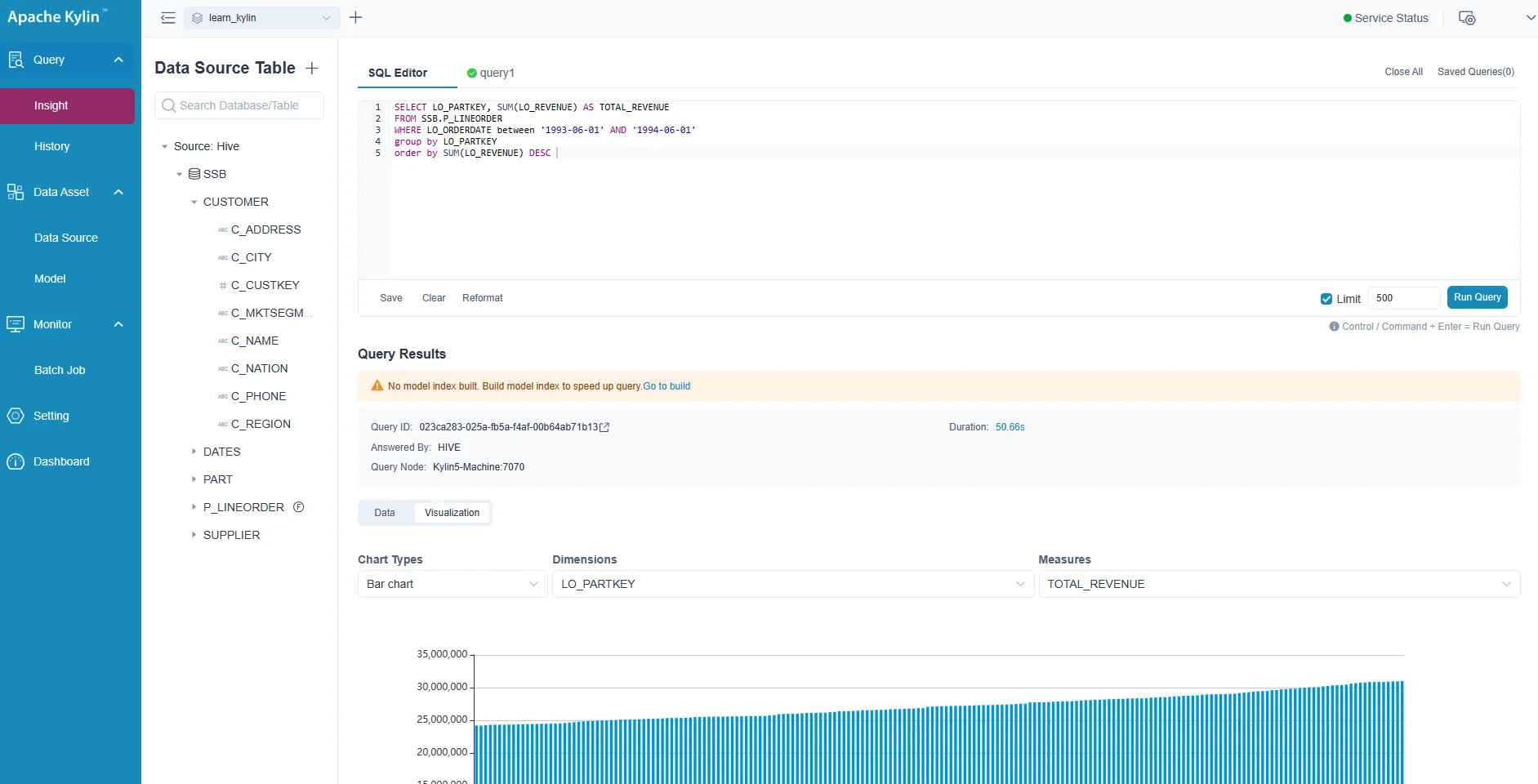
Query the data
Run the following sample query in the SQL editor:
SELECT LO_PARTKEY, SUM(LO_REVENUE) AS TOTAL_REVENUE
FROM SSB.P_LINEORDERWHERE LO_ORDERDATE between '1993-06-01' AND '1994-06-01' group by LO_PARTKEYorder by SUM(LO_REVENUE) DESC
The output looks like the following screenshot:
Stop the container
To stop the container, please run the following command:
docker stop Kylin5-Machine
Remove the container
If you also want to remove the container, please run the following command:
docker rm Kylin5-Machine
Summary
If you are building cubes for your OLAP projects on traditional relational database and would like to migrate over to a big data, horizontally scalable platform, Apache Kylin can be a good choice.