Spark is an analytics engine for big data processing. There are various ways to connect to a database in Spark.
This page summarizes some of common approaches to connect to SQL Server using Python as programming language.
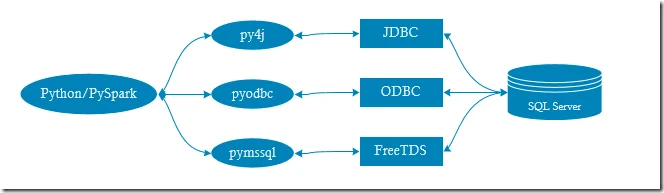
For each method, both Windows Authentication and SQL Server Authentication are supported. In the samples, I will use both authentication mechanisms.
All the examples can also be used in pure Python environment instead of running in Spark.
Prerequisites
I am using a local SQL Server instance in a Windows system for the samples. Both Windows Authentication and SQL Server Authentication are enabled.
For SQL Server Authentication, the following login is available:
- Login Name: zeppelin
- Password: zeppelin
- Access: read access to test database.
ODBC Driver 13 for SQL Server is also available in my system.
Via JDBC driver for SQL Server
Download Microsoft JDBC Driver for SQL Server from the following website:
Copy the driver into the folder where you are going to run the Python scripts. For this demo, the driver path is**‘sqljdbc_7.2/enu/mssql-jdbc-7.2.1.jre8.jar’**.
Code example
Use the following code to setup Spark session and then read the data via JDBC.
from pyspark import SparkContext, SparkConf, SQLContext
appName = "PySpark SQL Server Example - via JDBC"
master = "local"
conf = SparkConf() \
.setAppName(appName) \
.setMaster(master) \
.set("spark.driver.extraClassPath","sqljdbc_7.2/enu/mssql-jdbc-7.2.1.jre8.jar")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
spark = sqlContext.sparkSession
database = "test"
table = "dbo.Employees"
user = "zeppelin"
password = "zeppelin"
jdbcDF = spark.read.format("jdbc") \
.option("url", f"jdbc:sqlserver://localhost:1433;databaseName={database}") \
.option("dbtable", "Employees") \
.option("user", user) \
.option("password", password) \
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver") \
.load()
jdbcDF.show()
The output in my environment:
I would recommend using Scala if you want to use JDBC unless you have to use Python.
Via ODBC driver and pyodbc package
Install the package use this command:
pip install pyodbc
For documentation about pyodbc, please go to the following page:
Code example
from pyspark import SparkContext, SparkConf, SQLContext
import pyodbc
import pandas as pd
appName = "PySpark SQL Server Example - via ODBC"
master = "local"
conf = SparkConf() \
.setAppName(appName) \
.setMaster(master)
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
spark = sqlContext.sparkSession
database = "test"
table = "dbo.Employees"
user = "zeppelin"
password = "zeppelin"
conn = pyodbc.connect(f'DRIVER={{ODBC Driver 13 for SQL Server}};SERVER=localhost,1433;DATABASE={database};UID={user};PWD={password}')
query = f"SELECT EmployeeID, EmployeeName, Position FROM {table}"
pdf = pd.read_sql(query, conn)
sparkDF = spark.createDataFrame(pdf)
sparkDF.show()
In this example, Pandas data frame is used to read from SQL Server database. As not all the data types are supported when converting from Pandas data frame work Spark data frame, I customised the query to remove a binary column (encrypted) in the table.
Windows Authentication
Change the connection string to use Trusted Connection if you want to use Windows Authentication instead of SQL Server Authentication.
conn = pyodbc.connect(f'DRIVER={{ODBC Driver 13 for SQL Server}};SERVER=localhost,1433;DATABASE={database};Trusted_Connection=yes;')
Via pymssql
If you don’t want to use JDBC or ODBC, you can use pymssql package to connect to SQL Server.
Install the package use this command:
pip install pymssql
Code example
from pyspark import SparkContext, SparkConf, SQLContext
import _mssql
import pandas as pd
appName = "PySpark SQL Server Example - via pymssql"
master = "local"
conf = SparkConf() \
.setAppName(appName) \
.setMaster(master)
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
spark = sqlContext.sparkSession
database = "test"
table = "dbo.Employees"
user = "zeppelin"
password = "zeppelin"
conn = _mssql.connect(server='localhost:1433', user=user, password=password,database=database)
query = f"SELECT EmployeeID, EmployeeName, Position FROM {table}"
conn.execute_query(query)
rs = [ row for row in conn ]
pdf = pd.DataFrame(rs)
sparkDF = spark.createDataFrame(pdf)
sparkDF.show()
conn.close()
The above scripts first establishes a connection to the database and then execute a query; the results of the query is then stored in a list which is then converted to a Pandas data frame; a Spark data frame is then created based on the Pandas data frame.
Summary
You can also use JDBC or ODBC drivers to connect to any other compatible databases such as MySQL, Oracle, Teradata, Big Query, etc.