Turn data into
actionable insights faster.
Connect your data, bring your own LLM provider, and go from data questions to SQL, charts, and automated workflows — all in one workspace.
Databases
LLM Providers
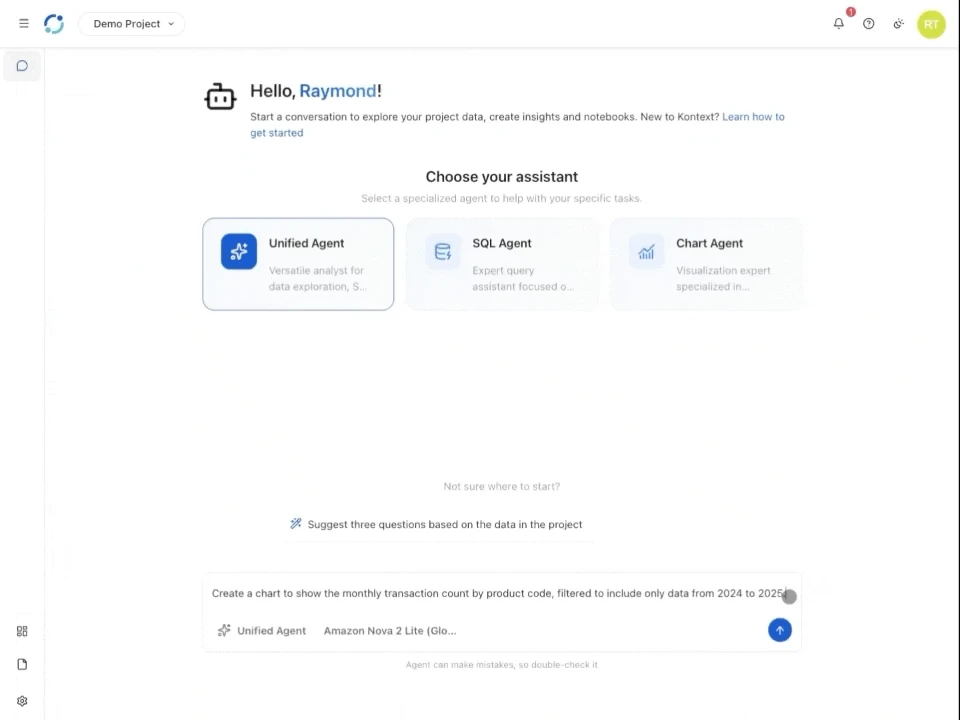
Everything you need for data analysis.
Connect data sources
Bring in project files, indexed knowledge documents, and familiar databases such as PostgreSQL and SQL Server from the same workspace.
Query your lakehouse
Keep data query-ready through a managed lakehouse layer built around a Built-in Iceberg Lakehouse and project-level catalog access.
Explore data lakeChoose your LLM provider
Run local open-weight models or connect hosted providers including OpenAI, Anthropic, Gemini, and Bedrock.
See providersHow it works
Three steps to unify your data, establish meaning with AI, and automate your repeatable workflows.
Connect
Start with files, external databases, and lakehouse-ready data in the same workspace.
Get startedAnalyze
Move from AI-assisted questions to SQL, charts, and notebooks without switching tools.
See notebooksAutomate
Turn useful analysis into repeatable workflows for monitoring, reporting, and follow-up tasks.
View workflowsReady to connect your data?
Start exploring your data with AI in minutes. No infrastructure setup required.
Latest Updates
Product changes, release notes, and practical guides.
Join Kontext Labs Platform Pilot
We invite Everyone—AI Enthusiasts, Business Owners, Researchers, Students, and Analysts—to join our pilot phase and help shape the future of data intelligence.