Slowly Changing Dimension has been commonly used in traditional data warehouse projects. It doesn't only save storage space but also make certain query pathways easier. Thus, in data lake context, it is still relevant. This article shows you how to implement a FULL merge into a delta SCD type 2 table with PySpark. It implements a true FULL merge to handle the DELETED records (NOT MATCHED BY SOURCE) while many other examples don't take this into consideration.
About SCD Type 2 dimension table
If you are not familiar with SCD Type 2 dimension, refer to this diagram on Kontext to learn more:
About FULL extract and merge

As the above diagramshows, a FULL extract usually extracts all the records from the source table, i.e. a snapshot of the table content as extract time. Compared with DELTA extract approach, there are no indication of deleted records. Thus, to implement a true FULL merge into a SCD Type 2 table, we need to compare with the target table to identify the deleted records.
For the current version of Delta Lake, it doesn't support the NOT MATCHED BY SOURCE clause; hence we need to do that comparison manually.
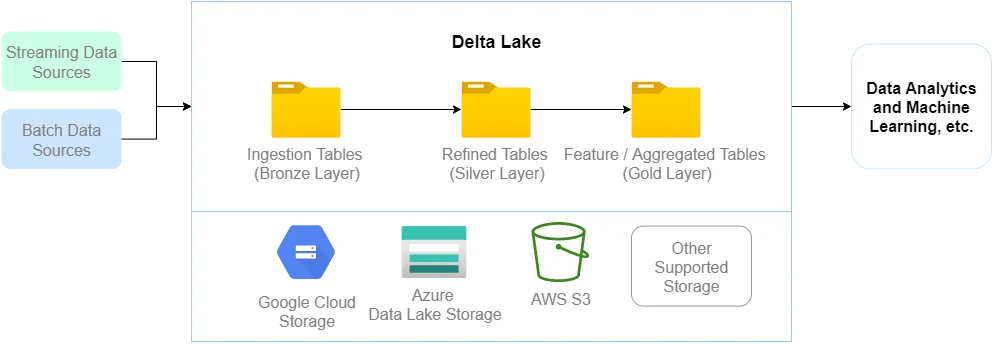
About Delta Lake
If you have no knowledge of Delta Lake storage format in Spark, refer to this article to learn more:
Delta Lake with PySpark Walkthrough
Implement FULL merge with delta table
Now let's dive into details.
Initialize a delta table
Let's start creating a PySpark with the following content. We will continue to add more code into it in the following steps.
from pyspark.sql import SparkSession
from delta.tables import *
from pyspark.sql.functions import *
import datetime
if __name__ == "__main__":
app_name = "PySpark Delta Lake - SCD2 Full Merge Example"
master = "local"
# Create Spark session with Delta extension
builder = SparkSession.builder.appName(app_name) \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.master(master)
spark = builder.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
delta_table_path = "/data/delta/scd2_table_full"
# Create a staging DataFrame for merge.
df_initial = spark.createDataFrame([['0001', 'Raymond'], ['0002', 'Kontext'], ['0003', 'John']
], ['customer_no', 'name'])
# Add default system/control columns per SCD type 2 specs
df_initial = df_initial.withColumn('is_current', lit(1))
init_load_ts = datetime.datetime.strptime(
'2022-01-01 00:00:00.000', '%Y-%m-%d %H:%M:%S.%f')
high_ts = datetime.datetime.strptime(
'9999-12-31 23:59:59.999', '%Y-%m-%d %H:%M:%S.%f')
df_initial = df_initial.withColumn('effective_ts', lit(init_load_ts))
df_initial = df_initial.withColumn('expiry_ts', lit(high_ts))
# For debug and demo purpose, no need for production jobs
df_initial.show(truncate=False)
# Save initial table as delta table
df_initial.write.format('delta').save(delta_table_path)
The script added delta lake support for the Spark session and then initialize a Type 2 table in Spark DataFrame. The data looks like the following:
+-----------+-------+----------+-------------------+-----------------------+
|customer_no|name |is_current|effective_ts |expiry_ts |
+-----------+-------+----------+-------------------+-----------------------+
|0001 |Raymond|1 |2022-01-01 00:00:00|9999-12-31 23:59:59.999|
|0002 |Kontext|1 |2022-01-01 00:00:00|9999-12-31 23:59:59.999|
|0003 |John |1 |2022-01-01 00:00:00|9999-12-31 23:59:59.999|
+-----------+-------+----------+-------------------+-----------------------+
In this DataFrame, column customer_no is the business key column. Column is_current is the flag to indicate whether the records are current active. As a initial load, the expiry_ts is set as a high timestamp.
The DataFrame is finally saved as Delta Lake table into the file system. We will use this delta table as target for a full merge.
Create a staging DataFrame/table
Let' continue to create a staging table for merge using the following code snippet:
# Create a staging table
df_stg = spark.createDataFrame([['0001', 'Ray'], ['0002', 'Kontext'], ['0004', 'Smith']
], ['customer_no', 'name'])
now = datetime.datetime.now()
df_stg = df_stg.withColumn('effective_ts', lit(now))
df_stg = df_stg.withColumn('expiry_ts', lit(high_ts))
df_stg = df_stg.withColumn('merge_key', df_stg['customer_no'])
df_stg = df_stg.withColumn('action', lit('U'))
# Cache it as we will use it in multiple actions
df_stg.cache()
# For debug and demo purpose, no need for production jobs
df_stg.show(truncate=False)
The staging DataFrame represents the source FULL extract (snapshot of the source table). We also added some columns with hard-coded values for easier merge later.
The DataFrame looks like the following:
+-----------+-------+--------------------------+-----------------------+---------+------+
|customer_no|name |effective_ts |expiry_ts |merge_key|action|
+-----------+-------+--------------------------+-----------------------+---------+------+
|0001 |Ray |2022-09-01 14:42:01.329717|9999-12-31 23:59:59.999|0001 |U |
|0002 |Kontext|2022-09-01 14:42:01.329717|9999-12-31 23:59:59.999|0002 |U |
|0004 |Smith |2022-09-01 14:42:01.329717|9999-12-31 23:59:59.999|0004 |U |
+-----------+-------+--------------------------+-----------------------+---------+------+
Column action is used to indicate what action needs to be applied later on when merging. We default it to 'U' (Updates) though not all the records will be updated later. The possible values for action column that will be used later are:
- U - Updates
- I - Inserts
- D - Deletes
The DataFrame tells us customer 0001 is updated, 0003 is deleted from source and 0004 is newly added.
We also added a column named merge_key which will be used to join to the target table. For tables with composite business keys, we can compute a hash value based on the composite key for merge. For hash functions in Spark, refer to Spark Hash Functions Introduction - MD5 and SHA.
Prepare a merge source DataFrame
As mentioned earlier, we need to take the DELETED records from source into consideration. To enable that, we will have to join to the target table to figure out those deleted ones. The following code snippet create a DataFrame that include the following records:
- Records with new business keys that will need to be inserted.
- Records that were deleted in source table.
- Records that are updated, which expire the current active records and insert new ones in. For this case, it means any records with column name updated.
The following is the code snippet:
# Find out records that needs to be inserted or deleted;
df_inerts_deletes = df_stg.alias('stg').join(df_tgt, on='customer_no', how='full')\
.where("""(current_tgt.is_current=1
AND current_tgt.name <> stg.name)
OR current_tgt.customer_no is null
OR stg.merge_key is null""") \
.select("customer_no", "stg.name", "stg.effective_ts", "stg.expiry_ts",
expr("""case when current_tgt.is_current is null
or current_tgt.name <> stg.name then 'I'
when stg.merge_key is null then 'D' end as action"""),
expr("""case when current_tgt.is_current is null
or current_tgt.name <> stg.name
then NULL
when stg.merge_key is null then customer_no
else stg.merge_key end as merge_key"""))
# For debug and demo purpose, no need for production jobs
df_inerts_deletes.show(truncate=False)
DataFrame df_inserts_deletes has the following content:
+-----------+-----+--------------------------+-----------------------+------+---------+
|customer_no|name |effective_ts |expiry_ts |action|merge_key|
+-----------+-----+--------------------------+-----------------------+------+---------+
|0001 |Ray |2022-09-01 14:42:01.329717|9999-12-31 23:59:59.999|I |null |
|0003 |null |null |null |D |0003 |
+-----------+-----+--------------------------+-----------------------+------+---------+
The output suggests:
- We will need to insert new record with new
effective_tsfor customer0001. - Customer
0003needs to be deleted.
This DataFrame itself is not sufficient for one single merge with delta table as we also need records to match with records that need to be expired. Hence we create a final source DataFrame by using this DataFrame with the staging DataFrame:
# Create a final staging table as src for merge
df_src = df_inerts_deletes.unionByName(df_stg)
df_src = df_src.withColumn('expiry_ts',
expr("""case when action='U'
then effective_ts - interval 0.001 seconds
else expiry_ts end"""))
# For debug and demo purpose, no need for production jobs
df_src.show(truncate=False)
For this consolidated DataFrame df_src, the content looks like the following:
+-----------+-------+--------------------------+--------------------------+------+---------+
|customer_no|name |effective_ts |expiry_ts |action|merge_key|
+-----------+-------+--------------------------+--------------------------+------+---------+
|0001 |Ray |2022-09-01 14:42:01.329717|9999-12-31 23:59:59.999 |I |null |
|0003 |null |null |null |D |0003 |
|0004 |Smith |2022-09-01 14:42:01.329717|9999-12-31 23:59:59.999 |I |null |
|0002 |Kontext|2022-09-01 14:42:01.329717|2022-09-01 14:42:01.328717|U |0002 |
|0004 |Smith |2022-09-01 14:42:01.329717|2022-09-01 14:42:01.328717|U |0004 |
+-----------+-------+--------------------------+--------------------------+------+---------+
Now let's merge into the final target table.
Implement the full merge
Use merge API to merge into the target delta table:
# Merge into customer_table
merge = customer_table.alias('tgt').merge(df_src.alias('src'),
"src.merge_key = tgt.customer_no") \
.whenMatchedUpdate(condition="tgt.is_current=1 AND src.name <> tgt.name",
set={"is_current": lit(0),
"expiry_ts": col('src.effective_ts')}) \
.whenMatchedUpdate(condition="tgt.is_current=1 AND src.action='D'",
set={"is_current": lit(0),
"expiry_ts":
expr('current_timestamp')}) \
.whenNotMatchedInsert(values={"customer_no": col("src.customer_no"),
"name": col("src.name"),
"is_current": lit(1),
"effective_ts": col("src.effective_ts"),
"expiry_ts": col("src.expiry_ts")
})
# Execute the merge
merge.execute()
customer_table.toDF().orderBy('customer_no', 'is_current',
'effective_ts').show(truncate=False)
There are a few things to pay attention to:
- Join condition is on
merge_keycolumn. - For the first
whenMatchedUpdate, we update the flagis_currentto 0 and also set theexpiry_tsas one millisecond less than the new record'seffective_ts. - For the second
whenMatchedUpdate, it softly deletes the current active record and marketexpiry_tsas current timestamp. - The last clause simply inserts the records that need to be inserted (incl. updated ones and also newly added ones).
Run the script, the target table will have the following content:
+-----------+-------+----------+--------------------------+--------------------------+
|customer_no|name |is_current|effective_ts |expiry_ts |
+-----------+-------+----------+--------------------------+--------------------------+
|0001 |Raymond|0 |2022-01-01 00:00:00 |2022-09-01 14:42:01.329717|
|0001 |Ray |1 |2022-09-01 14:42:01.329717|9999-12-31 23:59:59.999 |
|0002 |Kontext|1 |2022-01-01 00:00:00 |9999-12-31 23:59:59.999 |
|0003 |John |0 |2022-01-01 00:00:00 |2022-09-01 14:42:08.913 |
|0004 |Smith |1 |2022-09-01 14:42:01.329717|9999-12-31 23:59:59.999 |
|0004 |Smith |1 |2022-09-01 14:42:01.329717|2022-09-01 14:42:01.328717|
+-----------+-------+----------+--------------------------+--------------------------+
As we can tell the records are merged successfully as expected.
Summary
I hope you now understand how to implement a FULL merge with Delta Lake. One thing to pay attention to is that a FULL merge can be still costly as it needs to match the whole target table to find out the deleted ones. A more efficient SCD Type 2 implementation is to use DELTA merge with source that captures change data (CDC enabled). I will discuss more in future articles.
References
The following link provides an example of the traditional merge approach to implement a SCD type 2 without delta lake: