Hive 3.1.2 was released on 26th Aug 2019. It is still the latest 3.x release and works with Hadoop 3.x.y releases. In this article, I’m going to provide step by step instructions about installing Hive 3.1.2 on Windows 10.
warning Alert - Apache Hive is impacted by Log4j vulnerabilities; refer to page Apache Log4j Security Vulnerabilities to find out the fixes.
Prerequisites
Before installation of Apache Hive, please ensure you have Hadoop available on your Windows environment. We cannot run Hive without Hadoop.
Install Hadoop (mandatory)
I recommend to install Hadoop 3.3.0 to work with Hive 3.1.2 though any Hadoop 3.x version will work.
There are several articles I've published so far and you can follow one of them to install Hadoop in your Windows 10 machine:
- Install Hadoop 3.0.0 in Windows (Single Node)
- Install Hadoop 3.2.1 on Windows 10 Step by Step Guide
- (Recommended) Install Hadoop 3.3.0 on Windows 10 Step by Step Guide
Tools and Environment
- Windows 10
- Cygwin
- Command Prompt
Install Cygwin
Please install Cygwin so that we can run Linux shell scripts on Windows. From Hive 2.3.0, the binary doesn’t include any CMD file anymore. Thus you have to use Cygwin or any other bash/sh compatible tools to run the scripts.
You can install Cygwin from this site: https://www.cygwin.com/.
Download binary package
Download the latest binary from the official website:
For my location, the closest download is available at http://apache.mirror.serversaustralia.com.au/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz.
Save the downloaded package to a local drive. I am saving to ‘F:\big-data’. This path will be referenced in the instructions below. Please remember to replace it accordingly if you are saving to a different path.
If you cannot find the package, you can download from the archive site too: https://archive.apache.org/dist/hive/hive-3.1.2/.
Unpack the binary package
Open Cygwin terminal, and change directory (cd) to the folder where you save the binary package and then unzip:
cd F:\big-data tar -xvzf apache-hive-3.1.2-bin.tar.gz
The binaries are unzipped to path: F:\big-data\apache-hive-3.1.2-bin.
Setup environment variables
Run the following commands in Cygwin to setup the environment variables:
export HADOOP_HOME='/cygdrive/f/big-data/hadoop-3.3.0' export PATH=$PATH:$HADOOP_HOME/bin export HIVE_HOME='/cygdrive/f/big-data/apache-hive-3.1.2-bin' export PATH=$PATH:$HIVE_HOME/bin export HADOOP_CLASSPATH=$(hadoop classpath) export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*.jar
You can add these exports to file .bashrc so that you don’t need to run these command manually each time when you launch Cygwin:
vi ~/.bashrc
And then add the above lines into the file. If your Hadoop or Hive paths are different, please change them accordingly.
Run the following command to source the environment variables.
source ~/.bashrc
Start Hadoop daemon services
If you have not started Hadoop services yet, run the following commands in Command Prompt (Run as Administrator) window:
%HADOOP_HOME%\sbin\start-dfs.cmd
%HADOOP_HOME%\sbin\start-yarn.cmd
You should be able to see the following services via running jps command in Command Prompt:
jps
13024 NodeManager
18176 NameNode
10908 DataNode
1324 Jps
6284 ResourceManager
Setup Hive HDFS folders
Open Command Prompt and then run the following commands:
hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse
These commands will setup HDFS folders for Hive data warehousing.
Create a symbolic link
Java doesn’t understand Cygwin path properly. To avoid errors like the following, we need to add some symbolic links:
JAR does not exist or is not a normal file: F:\cygdrive\f\big-data\apache-hive-3.1.2-bin\lib\hive-beeline-3.1.2.jar
In my system, Hive is installed in F:\big-data\ folder. To make it work, follow these steps:
- Create a folder in F: driver named cygdrive
- Open Command Prompt (Run as Administrator) and then run the following command:
C:\WINDOWS\system32>mklink /J F:\cygdrive\f\ F:\ Junction created for F:\cygdrive\f\ <<===>> F:\
In this way, ‘F:\cygdrive\f’ will be equivalent to ‘*F:*’. You need to change the drive to the appropriate drive where you are installing Hive. For example, if you are installing Hive in C driver, the command line will be:
C:\WINDOWS\system32>mklink /J C:\cygdrive\c\ C:\
Initialize metastore
Now we need to initialize the schemas for metastore. The command syntax looks like the following:
$HIVE_HOME/bin/schematool -dbType <db type> -initSchema
Type the following command to view all the options:
$HIVE_HOME/bin/schematool -help
For argument dbType, the value can be one of the following databases:
derby|mysql|postgres|oracle|mssql
For this article, I am going to use derby as it is purely Java based and also already built-in with the Hive release:
$HIVE_HOME/bin/schematool -dbType derby -initSchema
infoIn some online guidance, they suggest to download Derby jar files. This is not required as they are already included in Hive release binary package.
The output looks similar to the following:

Ensure you can see the log 'schemaTool completed'.
A folder named metastore_db will be created on your current path (pwd). For my environment, it is F:\big-data\metastore_db.
Configure a remote database as metastore
This step is optional for this article. You can configure it to support multiple sessions.
Please refer to this post about configuring SQL Server database as metastore.
For this article, I am going to just use the Derby file system database.
Configure API authentication
Let's now add some configurations. All configuration files for Hive are stored in conffolder of HIVE_HOMEfolder.
- Create a configuration file named hive-site.xml using the following command in Cygwin:
cp $HIVE_HOME/conf/hive-default.xml.template $HIVE_HOME/conf/hive-site.xml
Open hive-site.xml file and remove all properties elements under root element 'configuration'.
Add the following configuration into hive-site.xml file.
<property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> <description> Should metastore do authorization against database notification related APIs such as get_next_notification. If set to true, then only the superusers in proxy settings have the permission </description> </property>
The content of the file looks like the following:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<!-- Hive Execution Parameters -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
<description>
Should metastore do authorization against database notification related APIs such as get_next_notification.
If set to true, then only the superusers in proxy settings have the permission
</description>
</property>
</configuration>
Alternatively you can configure proxy user in Hadoop core-site.xml configuration file. Refer to the following post for more details:
HiveServer2 Cannot Connect to Hive Metastore Resolutions/Workarounds
Start HiveServer2 service
Run the following command in Cygwin to start HiveServer2 service:
$HIVE_HOME/bin/hive --service metastore & $HIVE_HOME/bin/hive --service hiveserver2 start &
Leave the Cygwin terminal open so that the service keeps running and you can open another Cygwin terminal to run beelineor hivecommands. If you choose to use the following approach to start the service, press Ctrl + C to cancel this current one.
Run CLI directly
You can also run the CLI either via hive or beeline command.
$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT$HIVE_HOME/bin/hive
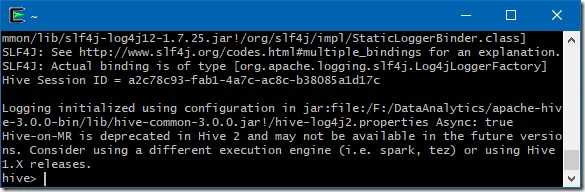
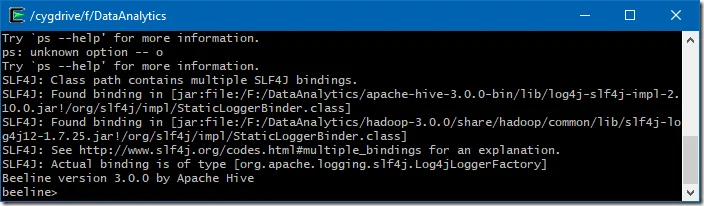
Replace $HS2_HOST with HiveServer2 address and $HS2_PORT with HiveServer2 port.
By default the URL is: jdbc:hive2://localhost:10000.
Verify Hive installation
Now we have Hive installed successfully, we can run some SQL commands to verify.
For more details about the commands, refer to official website:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients
Create a new Hive database
Run the following command in Beeline to create a database named test_db:
create database if not exists test_db;
As I didn’t specify the database location, it will be created under the default HDFS location: /user/hive/warehouse.
In HDFS name node, we can see a new folder is created as the following screenshot shows:

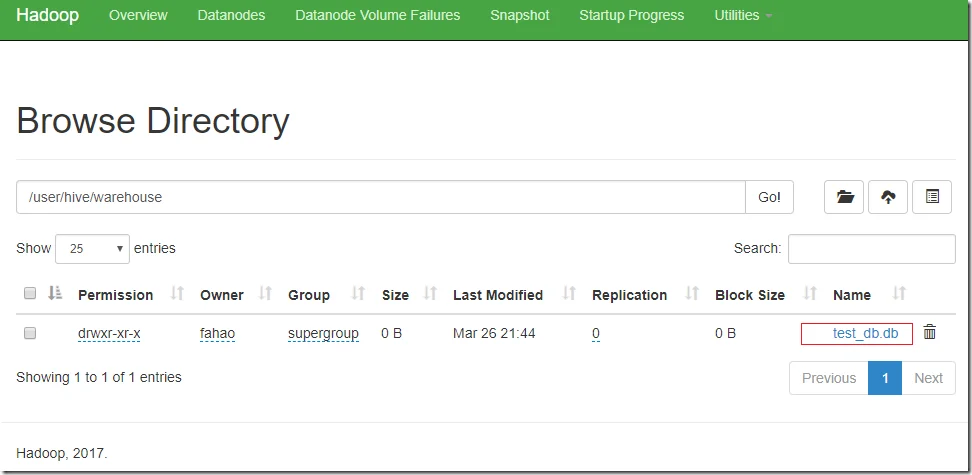
Create a new Hive table
Run the following commands to create a table named test_table:
use test_db;create table test_table (id bigint not null, value varchar(100));show tables;
Insert data into Hive table
Run the following command to insert some sample data:
insert into test_table (id,value) values (1,'ABC'),(2,'DEF');
Two records will be created by the above command.
The command will submit a MapReduce job to YARN. You can also configure Hive to use Spark as execution engine instead of MapReduce.
You can track the job status through Tracking URL printed out by the console output.
Go to YARN, you can also view the job status:

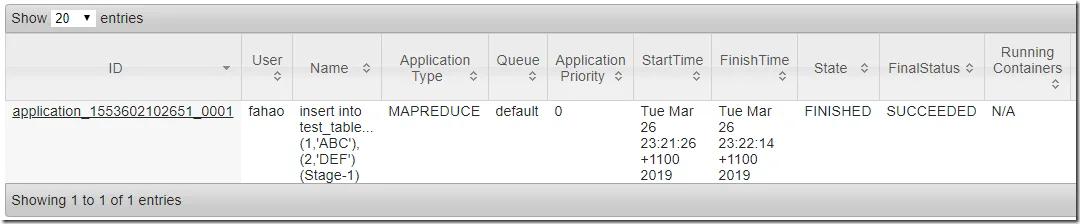
Wait until the job is completed.
Select data from Hive table
Now, you can display the data by running the following command in Beeline:
select * from test_table;
The output looks similar to the following:
+----------------+-------------------+ | test_table.id | test_table.value | +----------------+-------------------+ | 1 | ABC | | 2 | DEF | +----------------+-------------------+
In Hadoop NameNode website, you can also find the new files are created:

check Congratulations! You have successfully installed Hive 3.1.2 on your Windows 10 system.