Recently I've been developing servicing endpoints for local LLMs (Large Language Models) using Python FastAPI. To send model response to client in an streaming manner, I am using FastAPI's StreamingResponse function. However I encountered one error in client JavaScript: Error: Did not receive done or success response in stream. After searching for a few hours, I could not find any existing solutions to my problem. This was also due to the fact that I am not familiar with FastAPI (it is the first time I actually code heavily using FastAPI). Eventually I found a simple solution and hope it will save you sometime.
The streaming API
The following code snippet has the core logic of my streaming API:
async def chat(self, request: Request):
"""
Generate a chat response using the requested model.
"""
# Passing request body JSON to parameters of function _chat
# Request body follows ollama API's chat request format for now.
params = await request.json()
self.logger.debug("Request data: %s", params)
chat_response = self._client.chat(**params)
# Always return as streaming
if isinstance(chat_response, Iterator):
def generate_response():
for response in chat_response:
yield json.dumps(response)
return StreamingResponse(generate_response(), media_type="application/json")
elif chat_response is not None:
return json.dumps(chat_response)
The chatfunction in the above code snippet is designed to handle chat requests from client. Here's a simplified explanation of what it does:
- Receives a Request: It starts by receiving a request from a user. This request contains data in JSON format.
- Extracts Request Data: The function then reads the JSON data from the request.
- Logs the Request Data: It logs (records) the details of the request data for debugging purposes.
- Generates a Chat Response: Using the extracted request data, it calls another function
_client.chatto generate a response for the chat. This could involve processing the data, interacting with a chat model, or performing some other logic to produce a reply. - Checks the Response Type:
- If the response is an iterator (meaning it can produce a series of items over time, useful for streaming data), it creates a generator function named
generate_response. This generator function goes through each item in the response, converts it to JSON format, adds a newline character at the end, and yields it. This is useful for sending data back to the client piece by piece, rather than all at once. - If the response is not an iterator but contains some data, it directly converts this data into JSON format.
- If the response is an iterator (meaning it can produce a series of items over time, useful for streaming data), it creates a generator function named
- Returns the Response:
- For an iterator response, it returns a
StreamingResponsewith the generated content, indicating that the data should be streamed back to the client. - For a non-iterator response, it returns the JSON-formatted data directly.
- For an iterator response, it returns a
In summary, the chat function processes a chat request, generates a response based on the request data, and returns this response either as a stream (for iterable responses) or as a single JSON object.
In the browser, all the JSON was sent back to client together instead of streaming as the following screenshot shows:
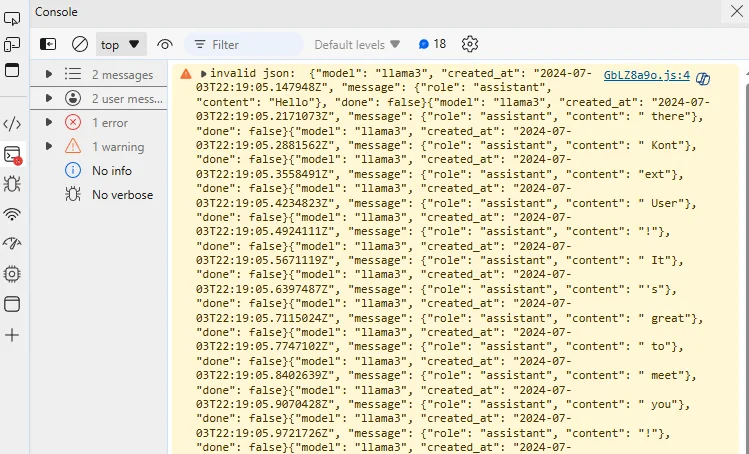
Changing response content type
By looking into Ollama's REST API response, I found it returns a different media type application/x-ndjson. Hence I changed the code to the following:
return StreamingResponse(generate_response(), media_type="application/x-ndjson")
Eventually I found this didn't work and application/json is ok too.
The solution
I also ensured _client.chat is returning an iterator. Finally I resolved the issue by adding a newline character in the response.
if isinstance(chat_response, Iterator):
def generate_response():
for response in chat_response:
yield json.dumps(response) + '\n'
It worked like a charm with application/json or application/x-ndjson. In browser developer tool, the JSON responses were also streaming back as expected.
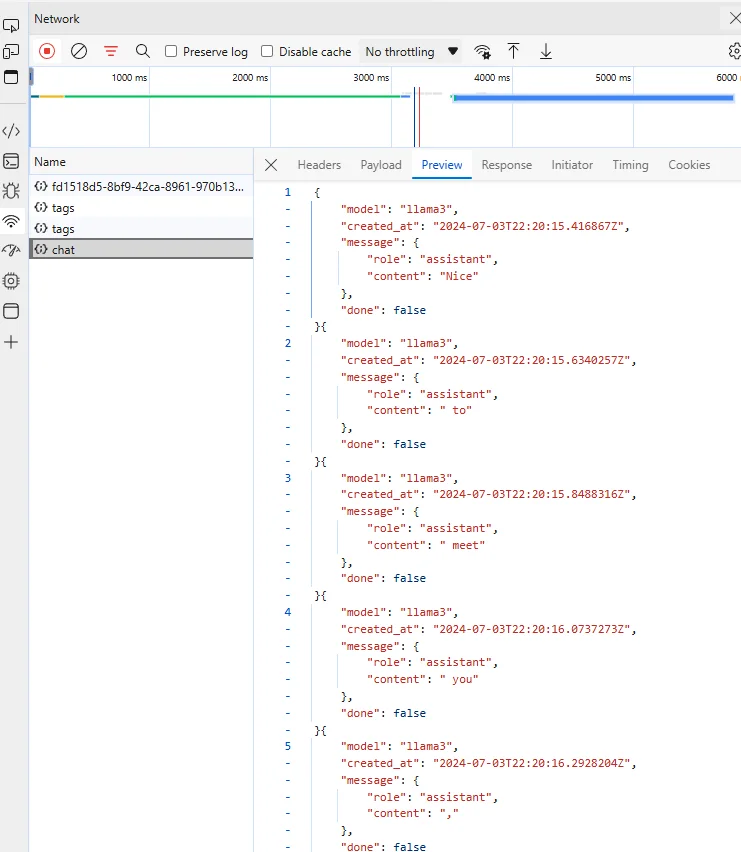 Hopefully this is helpful to you and you can use this approach in FastAPI to develop APIs that support streaming like the following chat example:
Hopefully this is helpful to you and you can use this approach in FastAPI to develop APIs that support streaming like the following chat example: