这篇文章将展示如果在Spark DataFrame中将一个JSON数组的字符串列转换为新的列。以下的示例代码均使用Spark 2.2.1;其它版本诸如 Spark 1.6.0 也可运行。
必要条件
如果您没有Spark的集群可以使用,您需要先在您的Windows或者其它系统中安装Spark。
*如果您使用Linux或者UNIX的系统,代码可以依然正常运行。
需求
将以下的串列数组转换为Spark DataFrame:
source = [{"attr_1": 1, "attr_2": "[{\"a\":1,\"b\":1},{\"a\":2,\"b\":2}]"}, {"attr_1": 2, "attr_2": "[{\"a\":3,\"b\":3},{\"a\":4,\"b\":4}]"}]
生成的DataFrame需要包含两列:
- attr_1: 类型为 IntegerType
- attr_2: 类型为 ArrayType (数组元素是StructType类型并且包含两个类型为StructField的字段)
DataFrame的架构应如下所示:
root |-- attr_1: long (nullable = true) |-- attr_2: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- a: integer (nullable = false) | | |-- b: integer (nullable = false)
解决方案
将串联转为DataFrame
首先我们使用以下代码将串列转换为Spark DataFrame:
# Read the list into data framedf = sqlContext.read.json(sc.parallelize(source))df.show()df.printSchema()
JSON数据被读取到DataFrame对象中。输入结果如下:
+------+--------------------+ |attr_1| attr_2| +------+--------------------+ | 1|[{"a":1,"b":1},{"...| | 2|[{"a":3,"b":3},{"...| +------+--------------------+root |-- attr_1: long (nullable = true) |-- attr_2: string (nullable = true)
数据集列attr_2是字符串类型而不是串列。
创建Python自定义函数用于解析JSON
对于attr_2列,让我们创建一个函数来解析其包含的字符串并将其从JSON转换为串列。我们需要用到json包。
# Function to convert JSON array string to a listimport jsondef parse_json(array_str):json_obj = json.loads(array_str)for item in json_obj: yield (item["a"], item["b"])
定于列attr\_2的架构
# Define the schemafrom pyspark.sql.types import ArrayType, IntegerType, StructType, StructFieldjson_schema = ArrayType(StructType([StructField('a', IntegerType(), nullable=False), StructField('b', IntegerType(), nullable=False)]))
根据以上的JSON字符串,我们将架构定义为一个结构体数组。
创建PySpark UDF
现在我们可以开始创建PySpark的自定义函数。我们需要用到之前定义的Python自定义函数 parse_json 以及架构变量json_schema。
# Define udffrom pyspark.sql.functions import udfudf_parse_json = udf(lambda str: parse_json(str), json_schema)
创建新的DataFrame
最后,我们将使用自定义的PySpark UDF来创建一个新的DataFrame:
# Generate a new data frame with the expected schemadf_new = df.select(df.attr_1, udf_parse_json(df.attr_2).alias("attr_2"))df_new.show()df_new.printSchema()
输出结果如下:
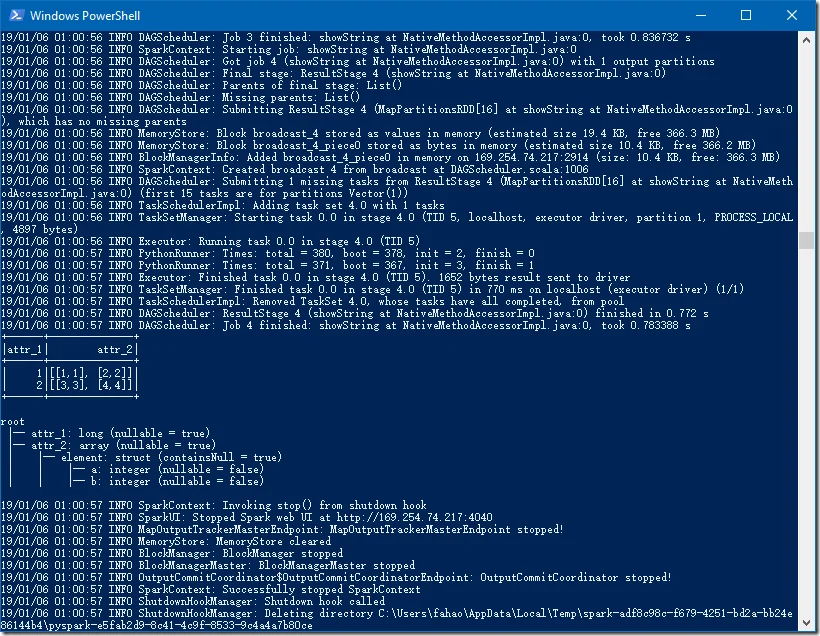
+------+--------------+ |attr_1| attr_2| +------+--------------+ | 1|[[1,1], [2,2]]| | 2|[[3,3], [4,4]]| +------+--------------+root |-- attr_1: long (nullable = true) |-- attr_2: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- a: integer (nullable = false) | | |-- b: integer (nullable = false)
总结
完整的代码如下:
from pyspark import SparkContext, SparkConf, SQLContextappName = "JSON Parse Example"master = "local[2]"conf = SparkConf().setAppName(appName).setMaster(master)sc = SparkContext(conf=conf)sqlContext = SQLContext(sc)source = [{"attr_1": 1, "attr_2": "[{\"a\":1,\"b\":1},{\"a\":2,\"b\":2}]"}, {"attr_1": 2, "attr_2": "[{\"a\":3,\"b\":3},{\"a\":4,\"b\":4}]"}]# Read the list into data framedf = sqlContext.read.json(sc.parallelize(source))df.show()df.printSchema()# Function to convert JSON array string to a listimport jsondef parse_json(array_str):json_obj = json.loads(array_str)for item in json_obj:yield (item["a"], item["b"])# Define the schemafrom pyspark.sql.types import ArrayType, IntegerType, StructType, StructFieldjson_schema = ArrayType(StructType([StructField('a', IntegerType(), nullable=False), StructField('b', IntegerType(), nullable=False)]))# Define udffrom pyspark.sql.functions import udfudf_parse_json = udf(lambda str: parse_json(str), json_schema)# Generate a new data frame with the expected schemadf_new = df.select(df.attr_1, udf_parse_json(df.attr_2).alias("attr_2"))df_new.show()df_new.printSchema()
将以上代码存在文件 parse_json.py; 然后您可以使用以下命令行提交到Spark中执行:
spark-submit parse_json.py
以下截图为我本机的输出结果(版本为:Spark 2.2.1, Python 3.6.4):
本文英文版本:PySpark: Convert JSON String Column to Array of Object (StructType) in Data Frame。