对于很多DBA和程序员来说,SQL Server中的索引不是一个陌生的事物,我们甚至每天都在使用它,对于哪些情况下应该创建索引都能一一的道出,不过有可能我们并没有仔细去想它的具体原理,本文将根据我对SQL Server中的索引的理解做一个简单的总结和概述,希望对大家能有所帮助(详细可参考《SQL Server 2005 Implementation and Maintenance》 )。
一,索引的作用 在SQL Server数据库中,当我们需要在大批量比如几亿条数据库中检索或者修改数据的时候,索引能够帮我们快速的找到目标数据。就如同我们要在字典中查找一个字的详细解释,如果没有索引,那么我们只有一页一页的查找,这样的速度是特别的慢的,当有了索引,我们可以快速的跳转到包含这个字的页,这样就大大的节省了时间。
二,SQL Server中创建索引的结构B-Tree/Banlanced Tree(B树)
我们思考一个问题,即便一本字典有索引是不是一定就能提高查阅速度呢?假如我们按照一个个字的在索引中找下去,那么几十万个字组成的索引也会花掉我们很长的时间;而现实生活告诉我们,一般我们的索引也是按照一定规律组成的,比如新华字典有按照生母排序的索引,也有按照笔画排序的索引,这样我们就能更快速的查阅,而不必要在索引中挨个字找下去。这里就要谈到B-Tree了,B-Tree也有类似的原理。
如下是B-Tree的示意图
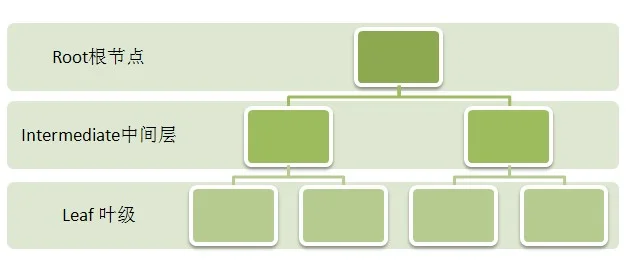 如上图B-Tree中只有一个根节点,这个根节点只包含一个数据页(data page);包含0个或者多个中间层,同时一个叶级。
在叶级的数据页中存储了创建索引的数据的相关信息(排序的);而每个叶级页所包含的索引行则要根据创建索引的列的数据类型来决定。
而中间层是将每个叶级页上的第一个输入索引值都存储在一个数据页上,并且存储对应叶级页的指针。而根节点存储的方式与此类似,存储的是每个中间层的第一个输入以及对应的指针。
如上图B-Tree中只有一个根节点,这个根节点只包含一个数据页(data page);包含0个或者多个中间层,同时一个叶级。
在叶级的数据页中存储了创建索引的数据的相关信息(排序的);而每个叶级页所包含的索引行则要根据创建索引的列的数据类型来决定。
而中间层是将每个叶级页上的第一个输入索引值都存储在一个数据页上,并且存储对应叶级页的指针。而根节点存储的方式与此类似,存储的是每个中间层的第一个输入以及对应的指针。
三、索引查找数据的实例
下面参考这个实例
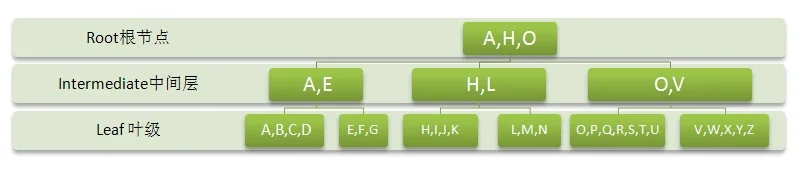 如果我们查找 “Man”这个单词,那么首先从根节点查找 这个时候值H和O都会被查找出来,由于L在O之前,所以这个时候会去 中间层级的H页查找 这个时候值L会被查找出来,然后在叶级页L查找到M。这样我们就仅查找了三个页,如果我们按照顺序查找,在上图中则需要查找5个页,在数据量很大的情况下优势会更明显。
如果我们查找 “Man”这个单词,那么首先从根节点查找 这个时候值H和O都会被查找出来,由于L在O之前,所以这个时候会去 中间层级的H页查找 这个时候值L会被查找出来,然后在叶级页L查找到M。这样我们就仅查找了三个页,如果我们按照顺序查找,在上图中则需要查找5个页,在数据量很大的情况下优势会更明显。
四、关于索引的级
我们知道在SQL Server中 一个数据页的大小是8192字节,用户最多只能存储 8060字节的数据。假如我们在一个char(60)的列上创建索引,在数据表中每一行则需要60字节的存储,同时这60字节也是索引每一行所占有的存储。 如果数据表中只有100行数据,那么总共的存储需要6000字节,这个时候仅需要一个数据页就可以了,那么这个数据页既是根节点也是叶级页。实际上,你可以在这个表中存储8060/60=134行数据,同时只需分配一个数据页来存储索引的值。 当你添加第135行数据的时候,这个时候一个数据页已经不能存储了,SQLServer就会增加两个数据页;这个操作就会创建包含一个根节点和两个叶级页的索引,两个叶级页分别各自包含一半数据,根节点页仅包含两行数据。这种情况下不需要中间层级页,因为根节点能够包含所有的叶级页第一个输入。这样一来,一次查询仅需要查询两个数据页就可以定位这个数据表中的任何一行。 当我们继续添加数据到这个表中,直到134*134+1=17957行数据。当有17956行数据的时候,这个时候根节点有134个叶级页,每个叶级页包含134个值。可是当添加第17957行数据的时候,这个根节点已经不能存储多余的数据了,否则就超过8060字节的限制了,这个时候 SQLServer会自动添加中间层级,这个层级包含两个数据页,每个数据页存储一半叶级页的第一行输入索引值,同时根节点页包含两行数据,分别为两个中间层级页的第一行数据索引值。 当第17956*134+1=2406105行数据添加到数据表中的时候,会再分配一个中间层级页。
通过上面的分析 我们可以发现即便是超过25亿数据的时候 每次查找也最多查找3个数据页就可以定位每一行数据了,这就是索引能够提高效率的原理。不过有一点就是创建索引需要分配额外的数据页用于存储索引值,所以会增加数据库的磁盘占有量,相比于性能的提升我觉得这方面可以不考虑。 我们还可以把同样的分析用于整形列创建索引的情况,这里就不再赘述了。
info说明:以上的总结中有些地方说得不是很清楚,这里做一个补充,避免大家混淆:索引还分为聚集索引和非聚集索引,上面提到的只有134行数据只需要一个数据页进行存储实际上是指的聚集索引的情况,这个时候叶级页上存储的是实际的数据;而如果是非聚集索引的情况那么实际的存储不止一个数据页 还需要给索引页分配存储。 聚集索引对表的物理数据页中的数据按列进行排序,然后再重新存储到磁盘上,即聚集索引与数据是混为一体的,它的叶节点中存储的是实际的数据。非聚集索引具有完全独立于数据行的结构,使用非聚集索引不用将物理数据页中的数据按列排序。非聚集索引的叶节点存储了组成非聚集索引的关键字值和行定位器。 关于聚集索引与非聚集索引我会在以后的文章中另做说明。