Spark是一个非常受欢迎的大数据处理分析的引擎。Spark提高很多种不同的方法用于连接到一个数据库用于读取数据。
本文将总结一些常用的方法以便连接到微软SQL Server数据库。本文中的例子均使用Python作为编程语言。
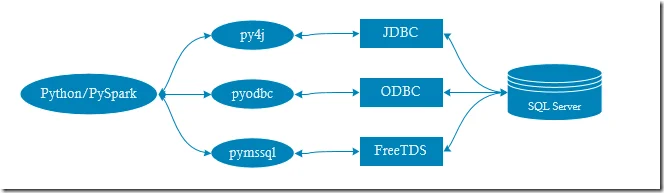
对于上图中的每一种方法,它们均提供两种验证模式:Windows集成验证以及SQL Server验证。在以下的示例中,我将使用两种不同的验证机制。
值得一提的是,本文中的所有示例都可以简单地转换为直接在纯粹的Python环境中运行,而无需在Spark中运行。
必要条件
我使用本机的一个SQL Server实例。数据库服务器中的Windows集成验证以及SQL Server验证均已开启。
对于SQL Server验证机制,我们将使用以下设置:
- 登录账号: zeppelin
- 密码:zeppelin
- 权限: 对于test数据库的只读权限**。**
SQL Server的ODBC驱动器版本13也包含在我的电脑中。
使用JDBC连接到SQL Server
首先请下载微软的SQL Server JDBC驱动器:
Download JDBC Driver (英文版本)
将下载后的驱动器文件放置在您将运行Python代码的文件夹中。对于本文的例子,路径为**‘sqljdbc_7.2/enu/mssql-jdbc-7.2.1.jre8.jar’。**
代码
使用以下代码创建SparkSession对象并且使用JDBC从SQL Server中读取数据:
from pyspark import SparkContext, SparkConf, SQLContext
appName = "PySpark SQL Server Example - via JDBC"
master = "local"
conf = SparkConf() \
.setAppName(appName) \
.setMaster(master) \
.set("spark.driver.extraClassPath","sqljdbc_7.2/enu/mssql-jdbc-7.2.1.jre8.jar")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
spark = sqlContext.sparkSession
database = "test"
table = "dbo.Employees"
user = "zeppelin"
password = "zeppelin"
jdbcDF = spark.read.format("jdbc") \
.option("url", f"jdbc:sqlserver://localhost:1433;databaseName={database}") \
.option("dbtable", "Employees") \
.option("user", user) \
.option("password", password) \
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver") \
.load()
jdbcDF.show()
以下截图是我的电脑中的运行结果:
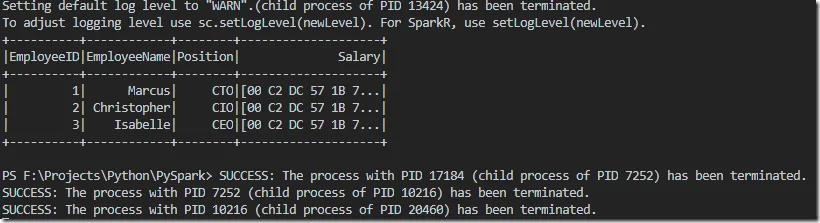
我推荐使用Scala作为编程语言如果你想要使用JDBC。
使用ODBC以及pyodbc包连接到SQL Server
首先请使用以下命令行安装pyodbc包:
pip install pyodbc
关于pyodbc的更多信息,请参考以下文档:
https://github.com/mkleehammer/pyodbc/wikihttps://github.com/mkleehammer/pyodbc/wiki (英文版本)
代码
from pyspark import SparkContext, SparkConf, SQLContext
import pyodbc
import pandas as pd
appName = "PySpark SQL Server Example - via ODBC"
master = "local"
conf = SparkConf() \
.setAppName(appName) \
.setMaster(master)
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
spark = sqlContext.sparkSession
database = "test"
table = "dbo.Employees"
user = "zeppelin"
password = "zeppelin"
conn = pyodbc.connect(f'DRIVER={{ODBC Driver 13 for SQL Server}};SERVER=localhost,1433;DATABASE={database};UID={user};PWD={password}')
query = f"SELECT EmployeeID, EmployeeName, Position FROM {table}"
pdf = pd.read_sql(query, conn)
sparkDF = spark.createDataFrame(pdf)
sparkDF.show()
在此示例中,Pandas DataFrame被用于读取SQL Server数据库中的数据。由于当转换Pandas DataFrame为Spark DataFrame时并不是所有数据类型都兼容,我将SQL语句修改了一下以便移除不被支持的SQL Server binary类型。
Windows集成验证
我们可以简单的将数据库连接字符串修改为Trusted Connection以使用Windows集成验证。
conn = pyodbc.connect(f'DRIVER={{ODBC Driver 13 for SQL Server}};SERVER=localhost,1433;DATABASE={database};Trusted_Connection=yes;')
使用pymssql
如果您不想使用JDBC或者ODBC,您可以直接使用pymssql包来连接到SQL Server数据库。
使用以下命令行以安装pymssql包:
pip install pymssql
代码
from pyspark import SparkContext, SparkConf, SQLContext
import _mssql
import pandas as pd
appName = "PySpark SQL Server Example - via pymssql"
master = "local"
conf = SparkConf() \
.setAppName(appName) \
.setMaster(master)
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
spark = sqlContext.sparkSession
database = "test"
table = "dbo.Employees"
user = "zeppelin"
password = "zeppelin"
conn = _mssql.connect(server='localhost:1433', user=user, password=password,database=database)
query = f"SELECT EmployeeID, EmployeeName, Position FROM {table}"
conn.execute_query(query)
rs = [ row for row in conn ]
pdf = pd.DataFrame(rs)
sparkDF = spark.createDataFrame(pdf)
sparkDF.show()
conn.close()
以上代码首先创建一个到目标数据库的连接,然后用其执行一条SQL语句;返回的串列结果然后被转换为Pandas的DataFrame;最好我们再将Pandas的DataFrame直接转换为Spark DataFrame。
总结
您也可以使用JDBC或者ODBC连接到其它受支持的数据库,比如MySQL,Oracle,Teradata,Big Query等等。