Microsoft Azure provides a number of data analytics related products and services. It allows users to tailor the solutions to meet different requirements, for example, architecture for modern data warehouse, advanced analytics with big data or real time analytics.
The following diagram shows a typical advanced analytics solution architecture on Azure.
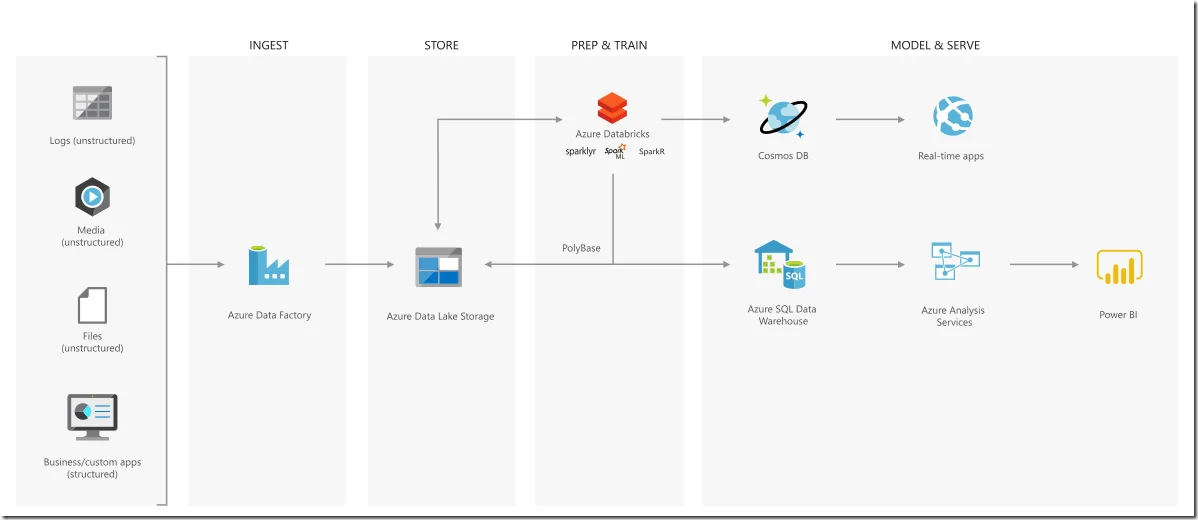
The architecture has four main layers:
- Ingest: Azure Data Factory is used for data ingestion. Azure Data Factory is a hybrid and serverless data integration (ETL) service which works with data wherever it lives, in the cloud or on-premises, with enterprise-grade security.
- Store: Data can be stored in Azure storage products including File, Disk, Blob, Queue, Archive and Data Lake Storage. Azure Data Lake Storage is a massively scalable data lake storage optimized for Apache Spark and Hadoop analytics engines.
- Prep & Train: In this layer, data can be cleaned and transformed using Azure Databricks. Databricks is an Apache Spark based analytics platform. Python, Scala, R and other language interpreters can be to analyse data. Spark machine learning libraries can also be used to create models.
- Model & Serve: After data preparation and transformation, the insights or output database can be written into Azure storage products or databases. Cosmos DB is Microsoft's globally distributed multi-model database. Azure SQL Data Warehouse is a massively parallel processing (MPP) data warehouse designed for the cloud. And then data can be consumed via applications or analysis services. Data stored in Azure Data Lake Storage can be also used in SQL Data Warehouse through PolyBase features in SQL Server.
Objectives
In this page, I am going to demonstrate how to ingest data from on-premise data to cloud by using Data Factory and then transform data using HDInsights before loading data into Azure SQL Data Warehouse. Eventually the data is consumed by Power BI.
The following diagram shows the steps required to complete the whole exercise.
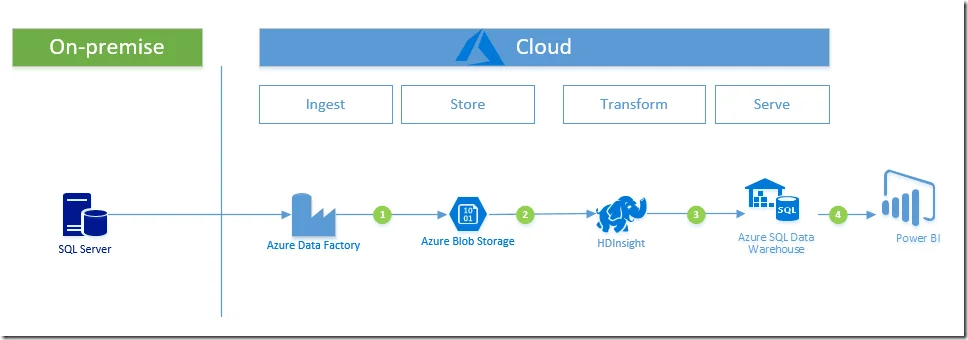
Prerequisites
- Azure subscription
- Azure storage account
- Azure HDInsights Spark cluster
- Azure SQL Data Warehouse instance (optional)
- Power BI (optional)
- Access to Azure portal
- On-premise SQL Server instance or any other data sources
Detailed steps
Create Azure Data Factory
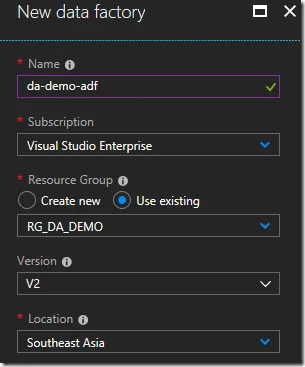
Once the resource is created, click Author & Monitor button to go to Azure Data Factory workspace.
The workspace looks like the following:
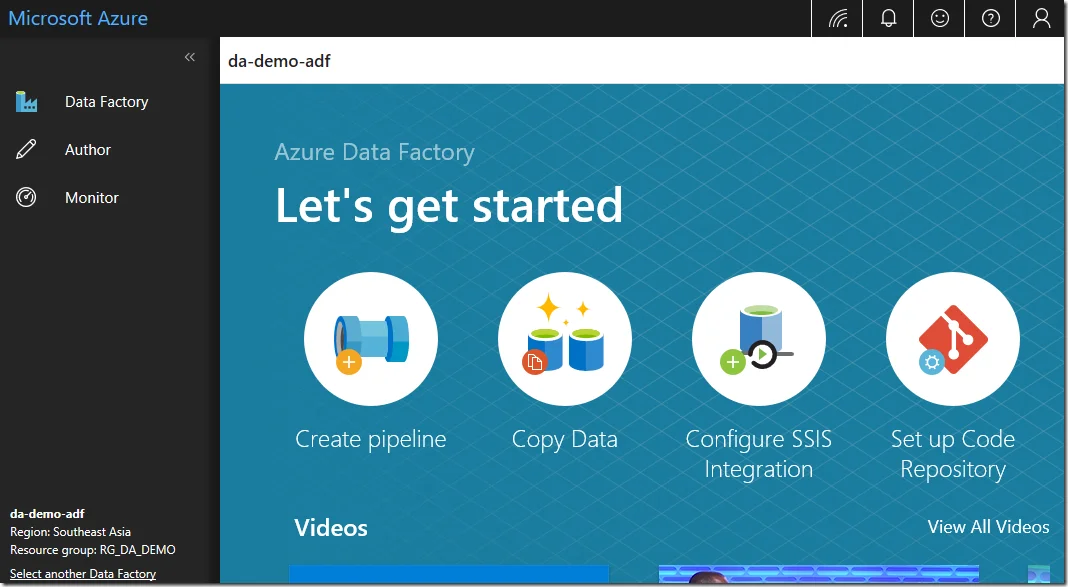
Create new pipeline
Click ‘Create pipeline’ button to create a new pipeline.
Create an activity to copy data from on-premise to Cloud
Drag ‘Copy Data’ activity from Data Transformation category to create an activity named CopyDataFromSQLServerToAzureBlobStorage.
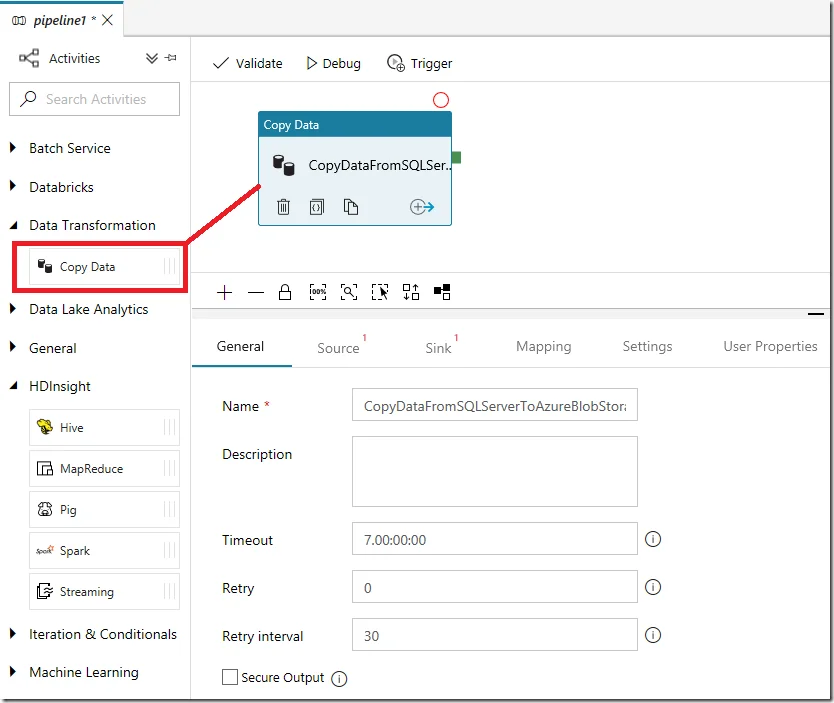
And then click Source tab to setup the source data.

Click ‘+ New button’ to create a new source.
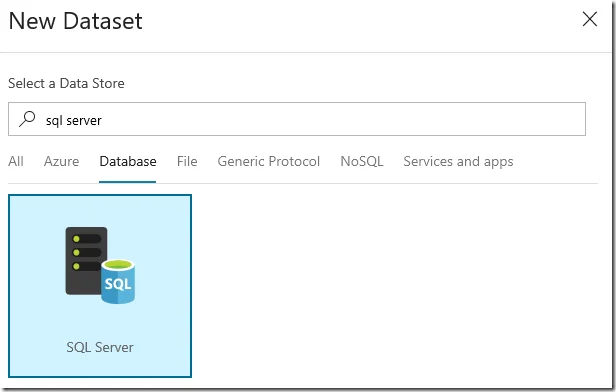
Select SQL Server as Data Store and then click Finish button to go to the dataset UI to setup the properties for the dataset.
Name the dataset as Premise_Mecury_Db_context_BlogPost:
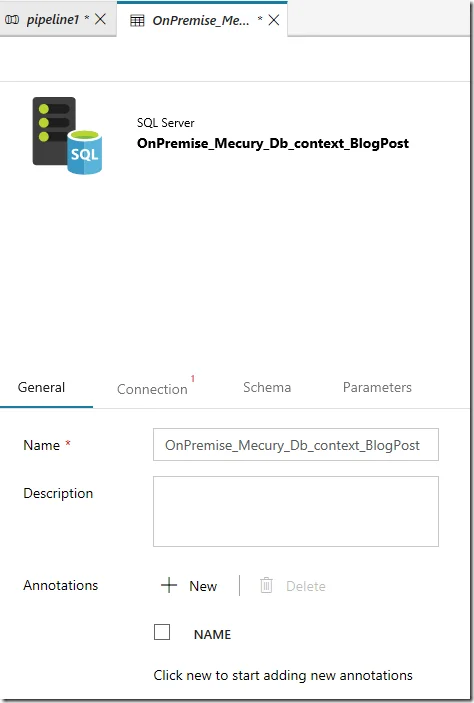
And then click Connection tab to setup the connection for the database.
Click the ‘+ New’ button to create a linked service.
And now follow step 6 to step 15 to setup the linked service in the following page:
https://docs.microsoft.com/en-us/azure/data-factory/tutorial-hybrid-copy-portal#create-a-pipeline
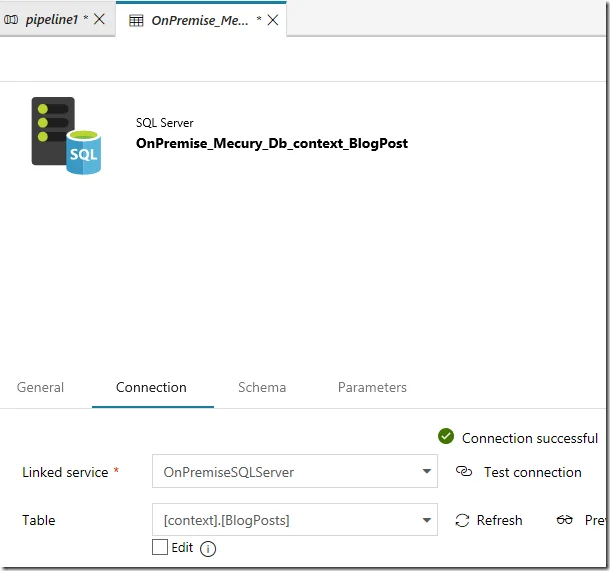
Once the setup is successful, you can select a table in your local SQL Server database.
For example, I am using context.BlogPosts as the source table:
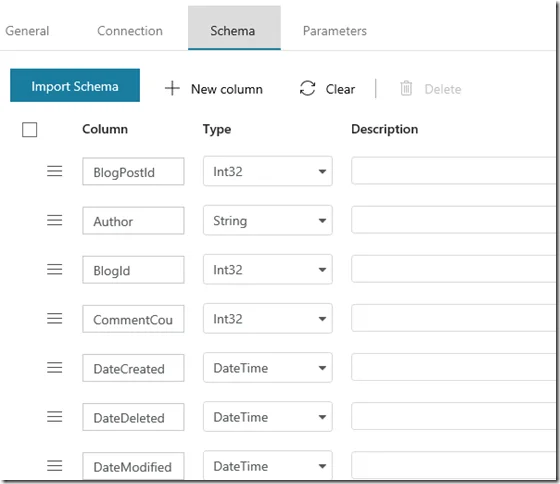
You can further detect the schema too as the following screenshot shows:
Go back to the pipeline:
Now we can setup the Sink.

Click button ‘+ New’ to create a new dataset.
This time we use Azure Blob Storage as Data Store:
Click Finish button to continue to edit this dataset:
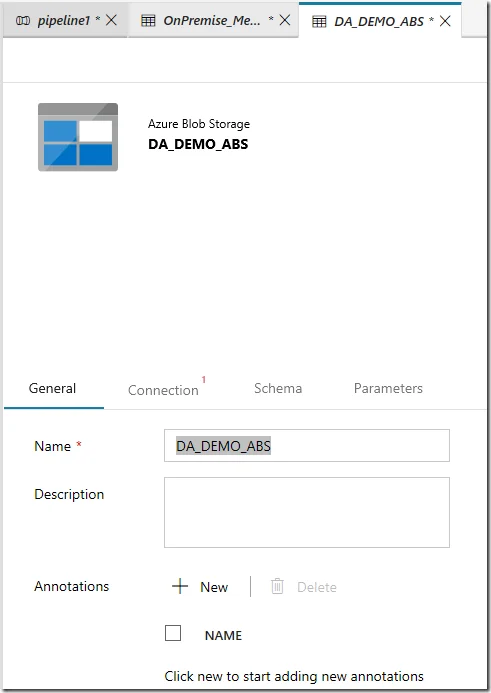
And then setup the Connection by creating a new linked service which connects to one of your existing storage. Use Parquet as file format.
You can also create a new storage account:
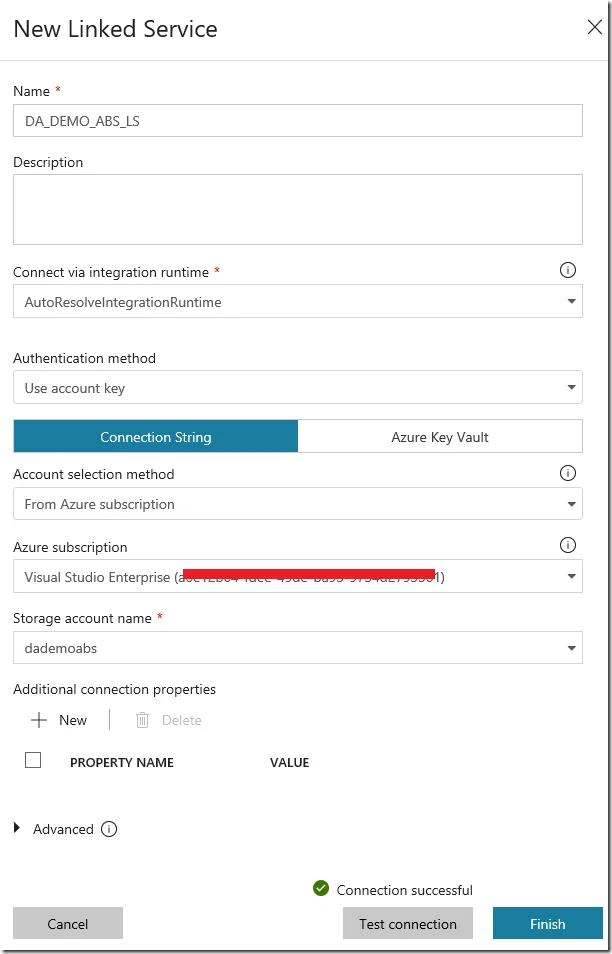
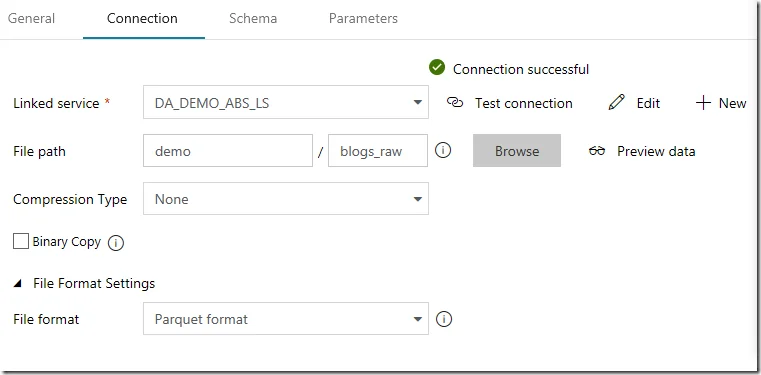
The following screenshot shows my settings for the linked service to Azure Blob Storage.
File path is also required for writing into blob:
Till now, we have completed the step to ingest data from on-premise SQL Server database into Cloud. The follow items are created in data factory:
- Data pipeline: pipeline1
- Dataset for on-premise data: OnPremise_Mecury_Db_context_BlogPost
- Dataset for Azure Blob Storage: DA_DEMO_ABS
Renamed the pipeline1 as DA-DEMO-Pipeline and then click Publish ALL button to publish.
Create a HDInsight Spark activity to transform data
Now drag a Spark activity into the pipeline:
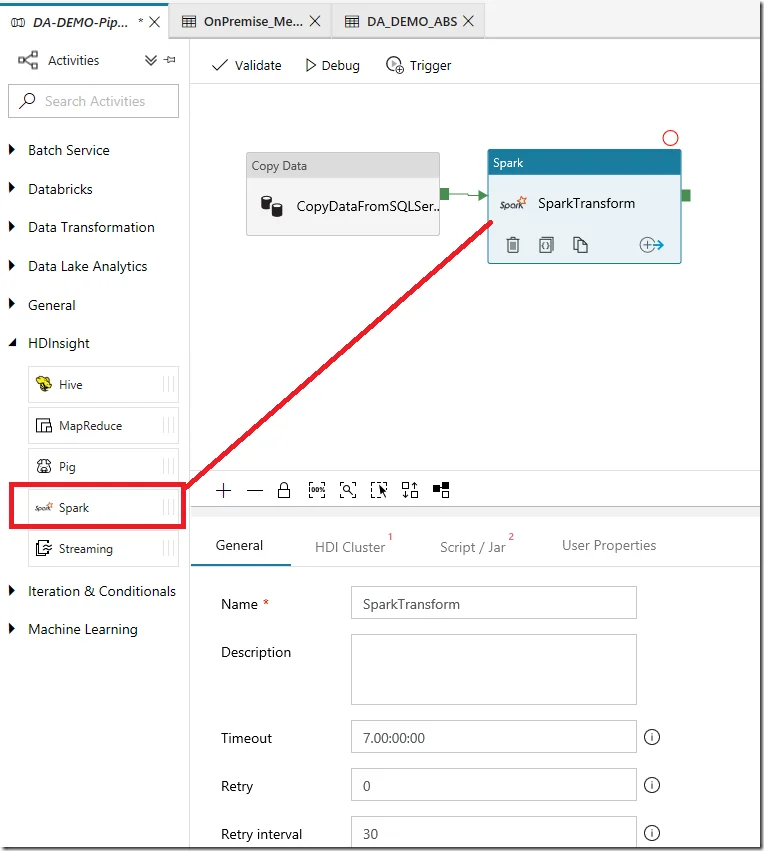
Now we need to configure the HDInsights cluster for this Spark activity.
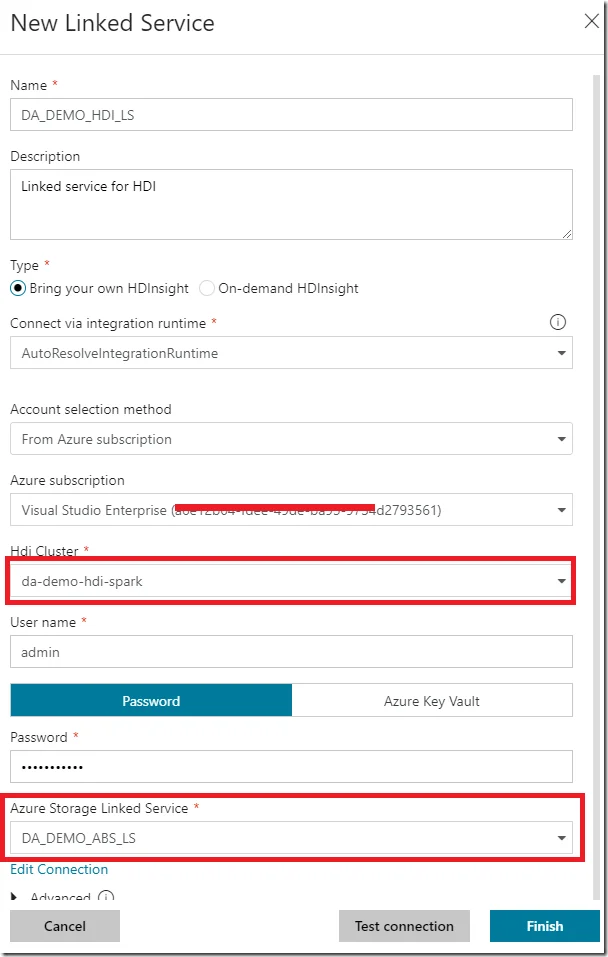
For this tutorial, I am using a predefined HDInsight cluster and also linking the Azure Storage to it too.
And then setup the script using the following code:
from pyspark.sql import SparkSession,SQLContext
spark = SparkSession.builder
.appName("SparkonADF - Transform")
.enableHiveSupport()
.getOrCreate()import here so that we can sql functions
from pyspark.sql.functions import *
blobPath="wasb://demo@dademoabs.blob.core.windows.net/blogs_raw" sqlContext = SQLContext(spark) #read back parquet to DF blogs = sqlContext.read.parquet(blobPath) blogs.registerTempTable("blogs")
transformation to add a new date column
blogs_new=sqlContext.sql("SELECT *, CAST(DatePublished AS DATE) AS DatePublished_DATE FROM blogs")
register temp table
blogs_new.registerTempTable("blogs_new")
save as new parquet files
blobPathNew="wasb://demo@dademoabs.blob.core.windows.net/blogs_transformed" blogs_new.write.mode("overwrite").parquet(blobPathNew);
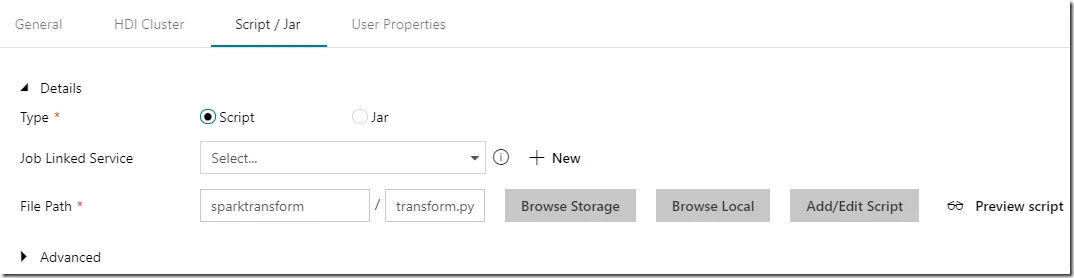
In my environment, the script file is named transform.py and is stored in sparktransform folder.
In YARN, we should be able to see the running application:

Create another Copy Data activity to write transformed data into Azure SQL Data Warehouse
You can now create another Copy Data activity to load transformed data into Azure SQL Data Warehouse (Sink).
For more details, please refer to https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-sql-data-warehouse
As I have limited credit for my current subscription, I will skip this step.
Visualize the data in Power BI
Now we can visualize the data through Power BI. No matter the transformed data is stored in Azure Blob Storage or Azure SQL Data Warehouse, Power BI has connectors available to get data from them.
HDInsights Spark can also be used as source too if we save the transformed data as table in Hive.
For example, the following code snippet shows how to save data frame as table:
Save as table
blogs_new.write.mode("overwrite").saveAsTable("blogs_transfomed")
In my case, I will use HDInsights Spark as source data for visualization.
The detailed steps about how to use HDInsights Spark as source are available here: https://docs.microsoft.com/en-us/power-bi/spark-on-hdinsight-with-direct-connect.
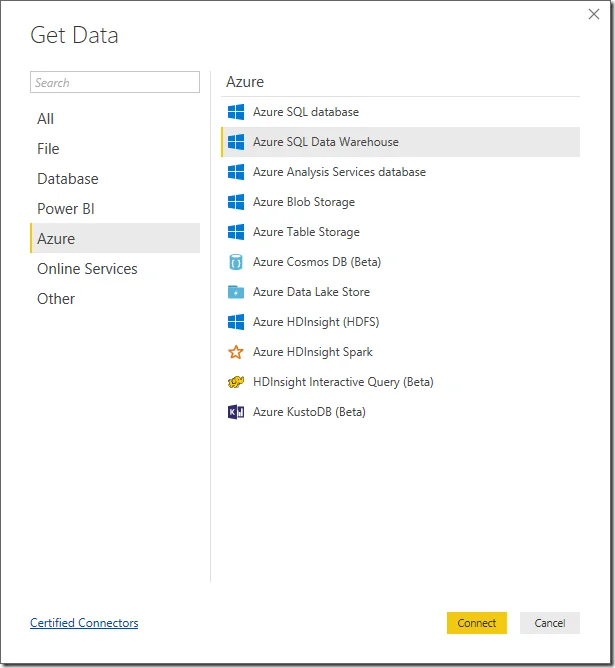
Input server:
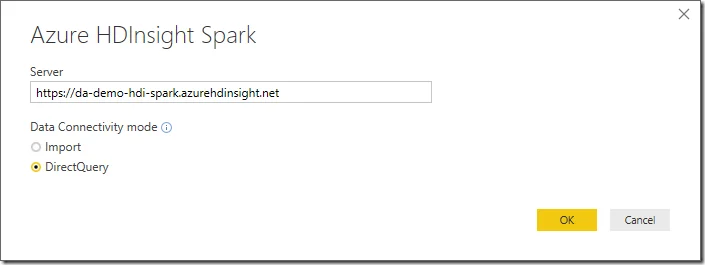
Click OK button to continue.
And then input user name and password:
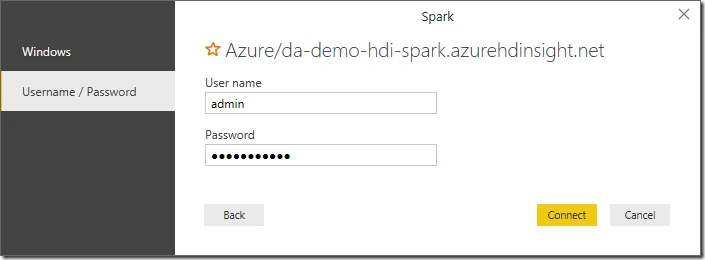
Click Connect button to continue.
The available Hive tables will show:
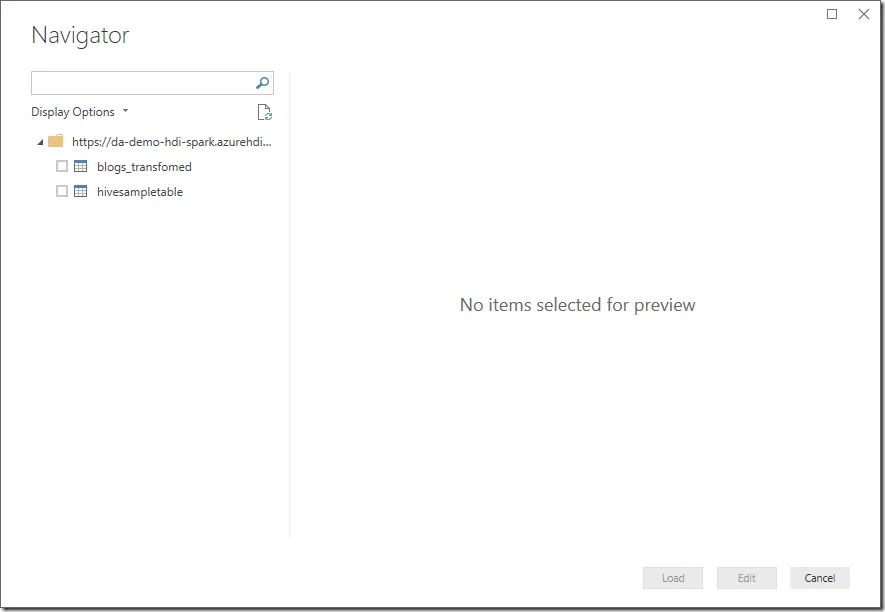 ]
]
In this case, select blogs_transformed as source.
Click Load button to load data into the workspace.
And then, we can visualize the data in Power BI:
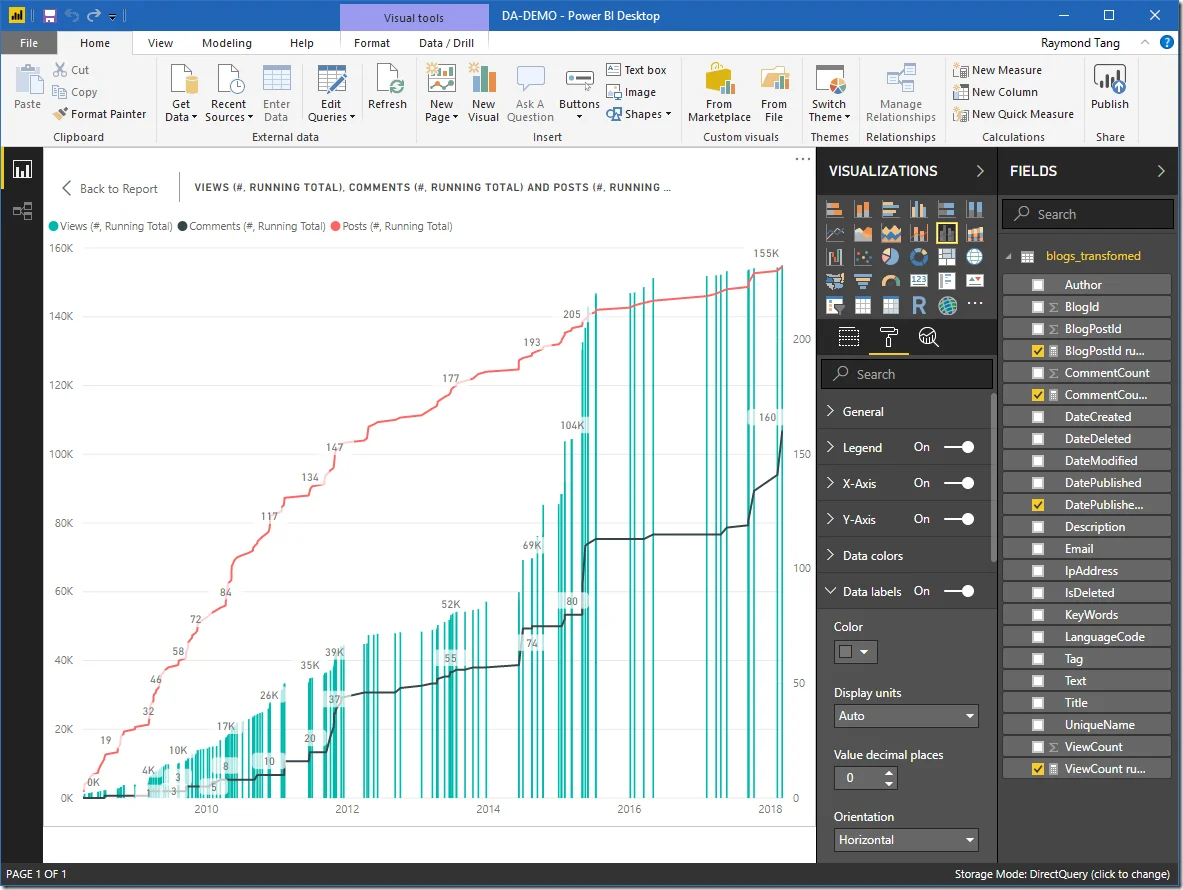
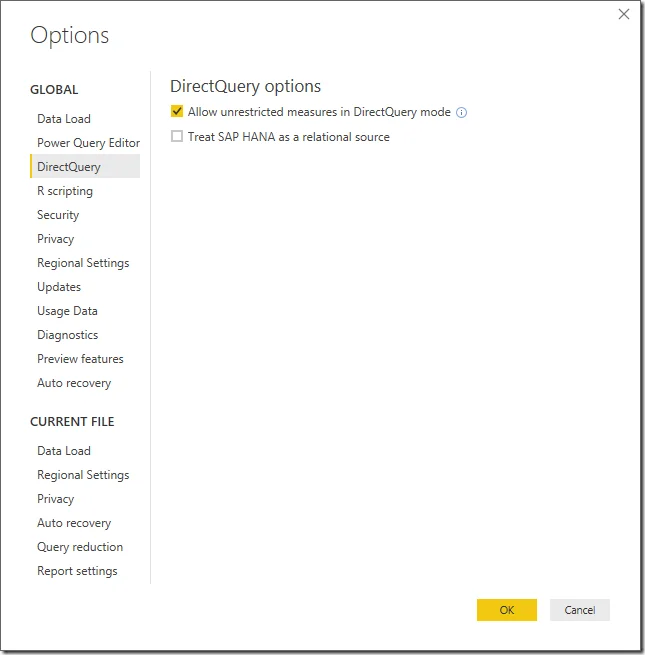
Remember to enable the following option if creating running total measures.
Once it is done, the report can also be published into powerbi.com:
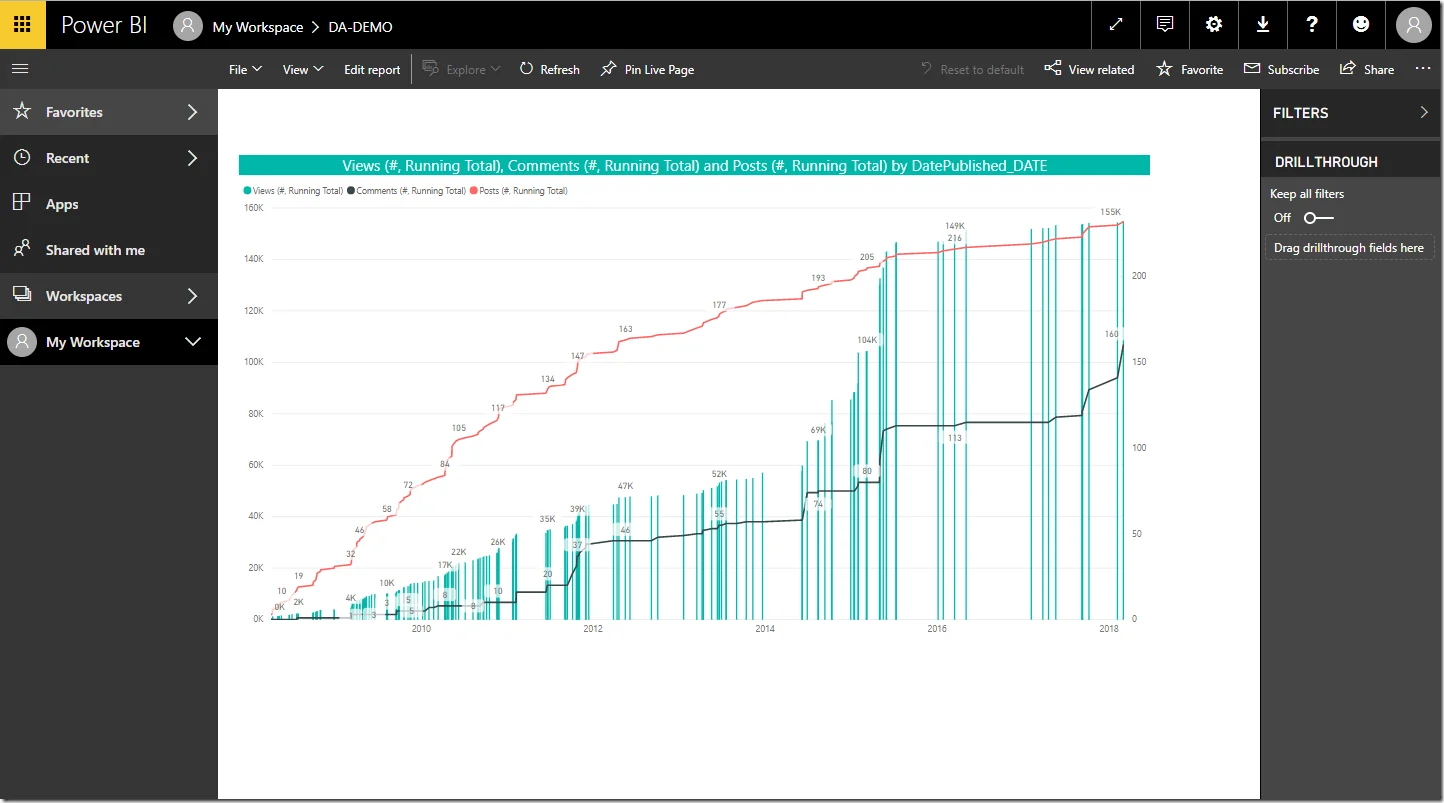
Once published, you can then view the report in the website:
Summary
With Azure Data Factory, it is very easy to move data between on-premises and cloud by using Copy Data activity; you can also use Spark, Databricks and ML activities to perform transformations or to create models.
The transformed data can then be stored in different storage products for different consumptions.