Install Hadoop 3.2.1 on Windows 10 Step by Step Guide
- References
- Required tools
- Step 1 - Download Hadoop binary package
- Select download mirror link
- Download the package
- Step 2 - Unpack the package
- Step 3 - Install Hadoop native IO binary
- Step 4 - (Optional) Java JDK installation
- Step 5 - Configure environment variables
- Configure JAVA_HOME environment variable
- Configure HADOOP_HOME environment variable
- Configure PATH environment variable
- Step 6 - Configure Hadoop
- Configure core site
- Configure HDFS
- Configure MapReduce and YARN site
- Step 7 - Initialise HDFS & bug fix
- About 3.2.1 HDFS bug on Windows
- Fix bug HDFS-14890
- Step 8 - Start HDFS daemons
- Step 9 - Start YARN daemons
- Step 10 - Useful Web portals exploration
- HDFS Namenode information UI
- HDFS Datanode information UI
- YARN resource manager UI
- Step 11 - Shutdown YARN & HDFS daemons
This detailed step-by-step guide shows you how to install the latest Hadoop (v3.2.1) on Windows 10. It's based on the previous articles I published with some updates to reflect the feedback collected from readers to make it easier for everyone to install.
Please follow all the instructions carefully. Once you complete the steps, you will have a shiny pseudo-distributed single node Hadoop to work with.
*The yellow elephant logo is a registered trademark of Apache Hadoop; the blue window logo is registered trademark of Microsoft.
References
Refer to the following articles if you prefer to install other versions of Hadoop or if you want to configure a multi-node cluster or using WSL.
- Install Hadoop 3.0.0 on Windows (Single Node)
- Configure Hadoop 3.1.0 in a Multi Node Cluster
- Install Hadoop 3.2.0 on Windows 10 using Windows Subsystem for Linux (WSL)
Required tools
Before you start, make sure you have these following tools enabled in Windows 10.
| Tool | Comments |
| PowerShell | We will use this tool to download package. In my system, PowerShell version table is listed below: $PSversionTable
Name Value
---- -----
PSVersion 5.1.18362.145
PSEdition Desktop
PSCompatibleVersions {1.0, 2.0, 3.0, 4.0...}
BuildVersion 10.0.18362.145
CLRVersion 4.0.30319.42000
WSManStackVersion 3.0
PSRemotingProtocolVersion 2.3
SerializationVersion 1.1.0.1 |
| Git Bash or 7 Zip | We will use Git Bash or 7 Zip to unzip Hadoop binary package. You can choose to install either tool or any other tool as long as it can unzip *.tar.gz files on Windows. |
| Command Prompt | We will use it to start Hadoop daemons and run some commands as part of the installation process. |
| Java JDK | JDK is required to run Hadoop as the framework is built using Java. In my system, my JDK version is jdk1.8.0_161. Check out the supported JDK version on the following page. https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions |
Now we will start the installation process.
Step 1 - Download Hadoop binary package
Select download mirror link
Go to download page of the official website:
Apache Download Mirrors - Hadoop 3.2.1
And then choose one of the mirror link. The page lists the mirrors closest to you based on your location. For me, I am choosing the following mirror link:
http://apache.mirror.digitalpacific.com.au/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
Download the package
Open PowerShell and then run the following command lines one by one:
$dest_dir="F:\big-data" $url = "http://apache.mirror.digitalpacific.com.au/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz" $client = new-object System.Net.WebClient $client.DownloadFile($url,$dest_dir+"\hadoop-3.2.1.tar.gz")
Once the download completes, you can verify it:
PS F:\big-data> cd $dest_dir
PS F:\big-data> ls
Directory: F:\big-data
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 18/01/2020 11:01 AM 359196911 hadoop-3.2.1.tar.gz
PS F:\big-data>You can also directly download the package through your web browser and save it to the destination directory.
Step 2 - Unpack the package
Now we need to unpack the downloaded package using GUI tool (like 7 Zip) or command line. For me, I will use git bash to unpack it.
Open git bash and change the directory to the destination folder:
cd F:/big-data
And then run the following command to unzip:
tar -xvzf hadoop-3.2.1.tar.gz
The command will take quite a few minutes as there are numerous files included and the latest version introduced many new features.
After the unzip command is completed, a new folder hadoop-3.2.1 is created under the destination folder.
tar: hadoop-3.2.1/lib/native/libhadoop.so: Cannot create symlink to ‘libhadoop.so.1.0.0’: No such file or directoryPlease ignore it for now as those native libraries are for Linux/UNIX and we will create Windows native IO libraries in the following steps.
Step 3 - Install Hadoop native IO binary
Hadoop on Linux includes optional Native IO support. However Native IO is mandatory on Windows and without it you will not be able to get your installation working. The Windows native IO libraries are not included as part of Apache Hadoop release. Thus we need to build and install it.
I also published another article with very detailed steps about how to compile and build native Hadoop on Windows: Compile and Build Hadoop 3.2.1 on Windows 10 Guide.
The build may take about one hourand to save our time, we can just download the binary package from github.
https://github.com/cdarlint/winutils
Download all the files in the following location and save them to the bin folder under Hadoop folder. For my environment, the full path is: F:\big-data\hadoop-3.2.1\bin. Remember to change it to your own path accordingly.
https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.1/bin
Alternatively, you can run the following commands in the previous PowerShell window to download:
$client.DownloadFile("https://github.com/cdarlint/winutils/raw/master/hadoop-3.2.1/bin/hadoop.dll",$dest_dir+"\hadoop-3.2.1\bin\"+"hadoop.dll")
$client.DownloadFile("https://github.com/cdarlint/winutils/raw/master/hadoop-3.2.1/bin/hadoop.exp",$dest_dir+"\hadoop-3.2.1\bin\"+"hadoop.exp")
$client.DownloadFile("https://github.com/cdarlint/winutils/raw/master/hadoop-3.2.1/bin/hadoop.lib",$dest_dir+"\hadoop-3.2.1\bin\"+"hadoop.lib")
$client.DownloadFile("https://github.com/cdarlint/winutils/raw/master/hadoop-3.2.1/bin/hadoop.pdb",$dest_dir+"\hadoop-3.2.1\bin\"+"hadoop.pdb")
$client.DownloadFile("https://github.com/cdarlint/winutils/raw/master/hadoop-3.2.1/bin/libwinutils.lib",$dest_dir+"\hadoop-3.2.1\bin\"+"libwinutils.lib")
$client.DownloadFile("https://github.com/cdarlint/winutils/raw/master/hadoop-3.2.1/bin/winutils.exe",$dest_dir+"\hadoop-3.2.1\bin\"+"winutils.exe")
$client.DownloadFile("https://github.com/cdarlint/winutils/raw/master/hadoop-3.2.1/bin/winutils.pdb",$dest_dir+"\hadoop-3.2.1\bin\"+"winutils.pdb")
After this, the bin folder looks like the following:
Step 4 - (Optional) Java JDK installation
Java JDK is required to run Hadoop. If you have not installed Java JDK please install it.
You can install JDK 8 from the following page:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Once you complete the installation, please run the following command in PowerShell or Git Bash to verify:
$ java -version java version "1.8.0_161" Java(TM) SE Runtime Environment (build 1.8.0_161-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
If you got error about 'cannot find java command or executable'. Don't worry we will resolve this in the following step.
Step 5 - Configure environment variables
Now we've downloaded and unpacked all the artefacts we need to configure two important environment variables.
Configure JAVA_HOME environment variable
As mentioned earlier, Hadoop requires Java and we need to configure JAVA_HOME environment variable (though it is not mandatory but I recommend it).
First, we need to find out the location of Java SDK. In my system, the path is: D:\Java\jdk1.8.0_161.
Your location can be different depends on where you install your JDK.
And then run the following command in the previous PowerShell window:
SETX JAVA_HOME "D:\Java\jdk1.8.0_161"
Remember to quote the path especially if you have spaces in your JDK path.
The output looks like the following:
Configure HADOOP_HOME environment variable
Similarly we need to create a new environment variable for HADOOP_HOME using the following command. The path should be your extracted Hadoop folder. For my environment it is: F:\big-data\hadoop-3.2.1.
If you used PowerShell to download and if the window is still open, you can simply run the following command:
SETX HADOOP_HOME $dest_dir+"/hadoop-3.2.1"
The output looks like the following screenshot:
Alternatively, you can specify the full path:
SETX HADOOP_HOME "F:\big-data\hadoop-3.2.1"
Now you can also verify the two environment variables in the system:
Configure PATH environment variable
Once we finish setting up the above two environment variables, we need to add the bin folders to the PATH environment variable.
If PATH environment exists in your system, you can also manually add the following two paths to it:
- %JAVA_HOME%/bin
- %HADOOP_HOME%/bin
Alternatively, you can run the following command to add them:
setx PATH "$env:PATH;$env:JAVA_HOME/bin;$env:HADOOP_HOME/bin"
If you don't have other user variables setup in the system, you can also directly add a Path environment variable that references others to make it short:
Close PowerShell window and open a new one and type winutils.exe directly to verify that our above steps are completed successfully:
You should also be able to run the following command:
hadoop -version java version "1.8.0_161" Java(TM) SE Runtime Environment (build 1.8.0_161-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
Step 6 - Configure Hadoop
Now we are ready to configure the most important part - Hadoop configurations which involves Core, YARN, MapReduce, HDFS configurations.
Configure core site
Edit file core-site.xml in %HADOOP_HOME%\etc\hadoop folder. For my environment, the actual path is F:\big-data\hadoop-3.2.1\etc\hadoop.
Replace configuration element with the following:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:19000</value>
</property> </configuration>
Configure HDFS
Edit file hdfs-site.xml in %HADOOP_HOME%\etc\hadoop folder.
Before editing, please correct two folders in your system: one for namenode directory and another for data directory. For my system, I created the following two sub folders:
- F:\big-data\data\dfs\namespace_logs
- F:\big-data\data\dfs\data
Replace configuration element with the following (remember to replace the highlighted paths accordingly):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///F:/big-data/data/dfs/namespace_logs</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///F:/big-data/data/dfs/data</value>
</property> </configuration>
In Hadoop 3, the property names are slightly different from previous version. Refer to the following official documentation to learn more about the configuration properties:
Configure MapReduce and YARN site
Edit file mapred-site.xml in %HADOOP_HOME%\etc\hadoop folder.
Replace configuration element with the following:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>%HADOOP_HOME%/share/hadoop/mapreduce/*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_HOME%/share/hadoop/common/*,%HADOOP_HOME%/share/hadoop/common/lib/*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/*,%HADOOP_HOME%/share/hadoop/hdfs/*,%HADOOP_HOME%/share/hadoop/hdfs/lib/*</value>
</property>
</configuration>
Edit file yarn-site.xml in %HADOOP_HOME%\etc\hadoop folder.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>Step 7 - Initialise HDFS & bug fix
Run the following command in Command Prompt
hdfs namenode -format
This command failed with the following error and we need to fix it:
2020-01-18 13:36:03,021 ERROR namenode.NameNode: Failed to start namenode.
java.lang.UnsupportedOperationException
at java.nio.file.Files.setPosixFilePermissions(Files.java:2044)
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:452)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:591)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:613)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:188)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1206)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1649)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1759)
2020-01-18 13:36:03,025 INFO util.ExitUtil: Exiting with status 1: java.lang.UnsupportedOperationExceptionRefer to the following sub section (About 3.2.1 HDFS bug on Windows) about the details of fixing this problem.
Once this is fixed, the format command (hdfs namenode -format) will show something like the following:
About 3.2.1 HDFS bug on Windows
This is a bug with 3.2.1 release:
https://issues.apache.org/jira/browse/HDFS-14890
It will be resolved in version 3.2.2 and 3.3.0.
We can apply a temporary fix as the following change diff shows:
I've done the following to get this temporarily fixed before 3.2.2/3.3.0 is released:
- Checkout the source code of Hadoop project from GitHub.
- Checkout branch 3.2.1
- Open pom file of hadoop-hdfs project
- Update class StorageDirectory as described in the above code diff screen shot:
if (permission != null) {
try {
Set<PosixFilePermission> permissions =
PosixFilePermissions.fromString(permission.toString());
Files.setPosixFilePermissions(curDir.toPath(), permissions);
} catch (UnsupportedOperationException uoe) {
// Default to FileUtil for non posix file systems
FileUtil.setPermission(curDir, permission);
}
}
- Use Maven to rebuild this project as the following screenshot shows:
Fix bug HDFS-14890
I've uploaded the JAR file into the following location. Please download it from the following link:
https://github.com/FahaoTang/big-data/blob/master/hadoop-hdfs-3.2.1.jar
And then rename the file name hadoop-hdfs-3.2.1.jar to hadoop-hdfs-3.2.1.bk in folder %HADOOP_HOME%\share\hadoop\hdfs.
Copy the downloaded hadoop-hdfs-3.2.1.jar to folder %HADOOP_HOME%\share\hadoop\hdfs.
Refer to this article for more details about how to build a native Windows Hadoop: Compile and Build Hadoop 3.2.1 on Windows 10 Guide.
Step 8 - Start HDFS daemons
Run the following command to start HDFS daemons in Command Prompt:
%HADOOP_HOME%\sbin\start-dfs.cmdTwo Command Prompt windows will open: one for datanode and another for namenode as the following screenshot shows:
Step 9 - Start YARN daemons
Alternatively, you can follow this comment on this page which doesn't require Administrator permission using a local Windows account:
https://kontext.tech/article/377/latest-hadoop-321-installation-on-windows-10-step-by-step-guide#comment314
Run the following command in an elevated Command Prompt window (Run as administrator) to start YARN daemons:
%HADOOP_HOME%\sbin\start-yarn.cmdSimilarly two Command Prompt windows will open: one for resource manager and another for node manager as the following screenshot shows:
Step 10 - Useful Web portals exploration
The daemons also host websites that provide useful information about the cluster.
HDFS Namenode information UI
http://localhost:9870/dfshealth.html#tab-overview
The website looks like the following screenshot:
HDFS Datanode information UI
http://localhost:9864/datanode.html
The website looks like the following screenshot:
YARN resource manager UI
http://localhost:8088
The website looks like the following screenshot:
Through Resource Manager, you can also navigate to any Node Manager:
Step 11 - Shutdown YARN & HDFS daemons
You don't need to keep the services running all the time. You can stop them by running the following commands one by one:
%HADOOP_HOME%\sbin\stop-yarn.cmd
%HADOOP_HOME%\sbin\stop-dfs.cmd
Let me know if you encounter any issues. Enjoy with your latest Hadoop on Windows 10.
Hello, welcome to Kontext!
In the configuration files, can you use the forward slash instead of backward slash?
file:///C:/BigData/data/dfs/namespace_logsThank you! Your fresh look was very helpful!
Hi, thanks for your tutorial
Everything is Ok
But, I get a error in last step. When I tried to start yarn by this command %HADOOP_HOME%\sbin\start-yarn.cmd
I got that error
How can I fix this?
Did you add bin folder into your PATH environment variable?
Btw, which version of Hadoop were you trying to install?
First, I am really sorry because this comment is in wrong topic. I follow install Hadoop by this topic (https://kontext.tech/article/829/install-hadoop-331-on-windows-10-step-by-step-guide). Sorry
..........
I am use hadoop 3.3.1 and this is my enviroment
And
I don't know why I got message "'C:\Program' is not recognized as an internal or external command, operable program or batch file.". But I think it is not problem.
I only get error in the step: Step 9 - Start YARN daemons, everything before is ok
For environment variable path with space, you can either quote the whole path C:\Program Files or using the short name:
C:\PROGRA~1
Thanks for your reply. I done it well
But how about my main question?
I can't start yarn
It looks like you have Node.js and yarn installed in your computer too. You can try temporary remove yarn from your system.
You can confirm this by typing:
which yarnDear Raymond Tang,
I checked the previous step and I realized I got an error on "Starting HDFS Deamond"
Anyway, I'm really happy for your help.Hope you alway success
I will comment my error in the exact post (https://kontext.tech/article/829/install-hadoop-331-on-windows-10-step-by-step-guide#comment1884, https://kontext.tech/comment/1884)
Hi.
What does this mean? here's the link to the full output https://www.dropbox.com/s/00rjsiyu8ezdf2w/yarn%20node%20manager.txt?dl=0
This is my output for the hive metastore , it showing warnings and no access to hiveserver2
https://www.dropbox.com/s/ec16lpp8d0tz1n9/--servicemetastoreoutput.txt?dl=0
2021-10-19 13:39:44,152 WARN nativeio.NativeIO: NativeIO.getStat error (3): The system cannot find the path specified.
-- file path: tmp/hadoop-User/nm-local-dir/filecache
2021-10-19 13:39:44,219 WARN nativeio.NativeIO: NativeIO.getStat error (3): The system cannot find the path specified.
-- file path: tmp/hadoop-User/nm-local-dir/usercache
2021-10-19 13:39:44,285 WARN nativeio.NativeIO: NativeIO.getStat error (3): The system cannot find the path specified.
-- file path: tmp/hadoop-User/nm-local-dir/nmPrivate
Hi, I'm using your guide with Hadoop 3.2.2 but when I compile the maven project with the command
mvn package -Pdist -DskipTests -Dtar -Dmaven.javadoc.skip=true
there is an error
Failed to execute goal org.codehaus.mojo:exec-maven-plugin:1.3.1:exec (pre-dist) on project hadoop-project-dist: Command execution failed.:
any idea about how to solve it?
thanks
Hi,
Can you please add more details so that I can help you?
For Hadoop build related questions, can you publish here:
Compile and Build Hadoop 3.2.1 on Windows 10 Guide - Hadoop Forum - Kontext
This article is about installing Hadoop with a pre-compiled binary package.
After I use the fix you mentioned namenode format still doesn't work
hdfs namenode -format
Error: Could not find or load main class org.apache.hadoop.hdfs.server.namenode.NameNode
The error you got indicates that Hadoop required JAR libraries are not loaded properly.
The fix I provided was for missing the right winutil native libs not JAR libs. Make sure your JAVA_HOME, HADDOP_HOME environment variables and other configurations are done properly. If you are not following all the steps in my article, I would suggest you follow this article.
Hi Ankit,
Yes, please refer to this series: https://kontext.tech/tag/big-data-on-windows-10.
It includes installation guide of Spark, Hive, Sqoop and Zeppelin on Windows.
-Raymond
Thank you so much.
I was struggling for Hadoop installation on my Windows, but your article helped me install it properly.
Just faced a small issue with resource manager, which I fixed by referring to the following link.
If possible, could you please update your blog with this entry also, that should make your article exhaustive :)
Thanks again :)
I'm glad it helped you. For the issue you mentioned, I don't think it is related to this tutorial. If you follow all the steps in this tutorial, you will not get that issue as this has been tested out by quite a few different people. I've also tested the steps in a new Windows 10 environment too.
It seems you may have mixed different versions of Hadoop libraries when doing the installation.
This installation guide is only for Hadoop 3.2.1. Can you confirm whether you exactly followed all the steps in this guide and also was using Hadoop 3.2.1 release for installation?
Hi Raymond,
Thanks for your reply :)
Looks like it may have happened due to mixing of different versions of Hadoop libraries. I started Hadoop installation by watching few YouTube videos (for older versions of Hadoop) where they later provided a modified version of bin folder. But my name-node was failing continuously. When I googled for the error message, I found your link and then followed the installation steps and could install Hadoop 3.2.1.
Thank you for taking out time to reply and clarify my confusion.
Regards,
Ankit
Hey, I saw an article about how to install Hadoop 3.3.0 on Windows in this website a couple days ago. But now it's gone. Was it deleted or is there a way for me to find it?
Further update:
I could not compile all Hadoop 3.3.0 projects on Windows 10 but I can compile the winutils project successfully.
You can follow this guide to install Hadoop 3.3.0 on Windows 10 without using WSL:
Install Hadoop 3.3.0 on Windows 10 Step by Step Guide
Alright. Cool. Thanks for replying.
Hi Andika,
I have just published the WSL version for Hadoop 3.3.0 installation on Windows 10:
Install Hadoop 3.3.0 on Windows 10 using WSL
The one you mentioned is about building Hadoop 3.3.0 on Windows 10. I have temporarily deleted it as I found some issues of building HDFS C/C++ project using CMake.
I'm still working on that and will publish the guide once I resolve the issues. There were some unexpected issues that I need to fix before I republish it.
Please stay tuned.
BTW, the Hadoop 3.2.1 build instructions are fully tested if you want to test something now.
Regards,
Raymond
Hi Raymond,
Ok I got my work IT helpdesk to add my ID to the Create Symbolic Links directory. That worked fine. So I am now passed the exitCode=1: CreateSymbolicLink error (1314): A required privilege is not held by the client. error.
Now, it is throwing this error:
Application application_1589579676240_0001 failed 2 times due to AM Container for appattempt_1589579676240_0001_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2020-05-15 17:57:08.681]Exception from container-launch.
Container id: container_1589579676240_0001_02_000001
Exit code: 1
Shell output: 1 file(s) moved.
"Setting up env variables"
"Setting up job resources"
"Copying debugging information"
C:\Users\V121119\Documents\Big-Data\tmp-nm\usercache\XXX\appcache\application_1589579676240_0001\container_1589579676240_0001_02_000001>rem Creating copy of launch script
C:\Users\V121119\Documents\Big-Data\tmp-nm\usercache\XXX\appcache\application_1589579676240_0001\container_1589579676240_0001_02_000001>copy "launch_container.cmd" "C:/Users/V121119/Documents/Big-Data/Hadoop/hadoop-3.2.1/logs/userlogs/application_1589579676240_0001/container_1589579676240_0001_02_000001/launch_container.cmd"
1 file(s) copied.
C:\Users\V121119\Documents\Big-Data\tmp-nm\usercache\XXX\appcache\application_1589579676240_0001\container_1589579676240_0001_02_000001>rem Determining directory contents
C:\Users\V121119\Documents\Big-Data\tmp-nm\usercache\XXX\appcache\application_1589579676240_0001\container_1589579676240_0001_02_000001>dir 1>>"C:/Users/XXX/Documents/Big-Data/Hadoop/hadoop-3.2.1/logs/userlogs/application_1589579676240_0001/container_1589579676240_0001_02_000001/directory.info"
"Launching container"
[2020-05-15 17:57:08.696]Container exited with a non-zero exit code 1. Last 4096 bytes of stderr :
'C:\Program' is not recognized as an internal or external command,
operable program or batch file.
[2020-05-15 17:57:08.696]Container exited with a non-zero exit code 1. Last 4096 bytes of stderr :
'C:\Program' is not recognized as an internal or external command,
operable program or batch file.
I think I know what is happening but don't know how to fix. One of my first errors was in hadoop.config.xml where it was trying to check if not exist %JAVA_HOME%\bin\java.exe but the problem is in path : C:\program files\Java\jre8 -Please note this directory "program files" has a space in it. The result was that I had to modify hadoop.config.xml to put double quotes around the check - making it
if not exist "%JAVA_HOME%\bin\java.exe" . This resolved that problem. Then another place I had found issue was on this line
for /f "delims=" %%A in ('%JAVA% -Xmx32m %HADOOP_JAVA_PLATFORM_OPTS% -classpath "%CLASSPATH%" org.apache.hadoop.util.PlatformName') do set JAVA_PLATFORM=%%A
This was messing up too for similar reason - it was erroring with similar error since some values in the classpath list were C:\program files\... and once it hit the space it blew up. For this line of code I just remarked it - since my HADOOP_JAVA_PLATFORM_OPTS is empty - I am not sure what I would have done had HADOOP_JAVA_PLATFORM_OPTS been populated. In any case, these were preliminary issues and all dealt with the fact that C:\program files... path was causing issues due to space. Therefore when I saw this latest exception, I am assuming it too is hitting this at java path or some member of classpath that has the same... but not sure where to modify - how to work around.
As of 5/15 6:10pm EDT - this is my current issue - you may disregard the prior comments if you wish since they are resolved... Thanks
Hi Tim,
In my computer, all the paths for HADDOP_HOME and JAVA_HOME are configured to a location without any space as I was worried that the spaces issue may cause problems in the applications.
That's also the reasons that most of Windows Hadoop installation guides recommend configuring them in a path that has no space. This is even more important for Hive installation.
So I think you are right the issue was due to the space in your environment variables.
JAVA_HOME environment variable is setup in the following folder:
%HADOOP_HOME%\etc\hadoop\hadoop-env.cmd
And also in Step 6 of this page, we've added class paths for JARs:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>%HADOOP_HOME%/share/hadoop/mapreduce/*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_HOME%/share/hadoop/common/*,%HADOOP_HOME%/share/hadoop/common/lib/*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/*,%HADOOP_HOME%/share/hadoop/hdfs/*,%HADOOP_HOME%/share/hadoop/hdfs/lib/*</value>
</property>
</configuration>You can try to change them to absolute values with double quotes to see if they work.
To save all the troubles, I would highly recommend getting Java available in a path without space or create a symbolic link to the Java folder in a location without space in the path.
Hello, sorry for the blow by blow here but I can't find a way to update existing comment.
I did find the correct version of winutils.exe that solves the two problems regarding both the WARN util.SysInfoWindows: Expected split length of sysInfo to be 11. Got 7
as well as the Exit code: 1639 Exception message: Incorrect command line arguments. issues.
(By the way that winutils version is found here: https://github.com/cdarlint/winutils/blob/master/hadoop-3.2.1/bin/winutils.exe)
So now I'm back to the insert in hive - when I try to run it my job fails with Exit code: 1 Exception message: CreateSymbolicLink error (1314): A required privilege is not held by the client. in my yarn resource manager I can find Container id: container_1589558742717_0001_02_000001 Exit code: 1Exception message: CreateSymbolicLink error (1314): A required privilege is not held by the client. as well. In my yarn node manager window I can see the same error as well as '2020-05-15 12:12:35,690 WARN nodemanager.NMAuditLogger: USER=myid OPERATION=Container Finished - Failed TARGET=ContainerImpl RESULT=FAILURE DESCRIPTION=Container failed with state: EXITED_WITH_FAILURE APPID=application_1589558742717_0001 CONTAINERID=container_1589558742717_0001_01_000001'
As I did not have a way to update my last comment I'm adding a new one. Regarding the winutils.exe maybe being wrong version.
At the command line I have issued the command
>winutils.exe systeminfo
23994769408,17015447552,3802951680,4812754944,8,2112000,149723796
This shows that indeed it is only returning 7, but something in this hadoop installation is expecting 11. That I think is proof that the winutils.exe I'm using is not the correct one. Although mine is compatible with 64bit, unlike some others I downloaded and tried, somewhere i need the version of this that will return 11 it seems.
hello Raymond,
I learning about Hadoop and was following your detailed information on windows installation.
2020-04-27 22:32:04,347 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-1d0c51aa-5dde-446b-99c1-3997255160fa
2020-04-27 22:32:05,369 INFO namenode.FSEditLog: Edit logging is async:true
2020-04-27 22:32:05,385 INFO namenode.FSNamesystem: KeyProvider: null
2020-04-27 22:32:05,387 INFO namenode.FSNamesystem: fsLock is fair: true
2020-04-27 22:32:05,388 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
2020-04-27 22:32:05,428 INFO namenode.FSNamesystem: fsOwner = saad (auth:SIMPLE)
2020-04-27 22:32:05,431 INFO namenode.FSNamesystem: supergroup = supergroup
2020-04-27 22:32:05,431 INFO namenode.FSNamesystem: isPermissionEnabled = true
2020-04-27 22:32:05,432 INFO namenode.FSNamesystem: HA Enabled: false
2020-04-27 22:32:05,535 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling
2020-04-27 22:32:05,554 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000
2020-04-27 22:32:05,554 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
2020-04-27 22:32:05,562 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2020-04-27 22:32:05,563 INFO blockmanagement.BlockManager: The block deletion will start around 2020 Apr 27 22:32:05
2020-04-27 22:32:05,566 INFO util.GSet: Computing capacity for map BlocksMap
2020-04-27 22:32:05,566 INFO util.GSet: VM type = 64-bit
2020-04-27 22:32:05,568 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB
2020-04-27 22:32:05,568 INFO util.GSet: capacity = 2^21 = 2097152 entries
2020-04-27 22:32:05,579 INFO blockmanagement.BlockManager: Storage policy satisfier is disabled
2020-04-27 22:32:05,580 INFO blockmanagement.BlockManager: dfs.block.access.token.enable = false
2020-04-27 22:32:05,588 INFO Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
2020-04-27 22:32:05,589 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
2020-04-27 22:32:05,589 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0
2020-04-27 22:32:05,589 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000
2020-04-27 22:32:05,591 INFO blockmanagement.BlockManager: defaultReplication = 1
2020-04-27 22:32:05,591 INFO blockmanagement.BlockManager: maxReplication = 512
2020-04-27 22:32:05,591 INFO blockmanagement.BlockManager: minReplication = 1
2020-04-27 22:32:05,592 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
2020-04-27 22:32:05,592 INFO blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms
2020-04-27 22:32:05,592 INFO blockmanagement.BlockManager: encryptDataTransfer = false
2020-04-27 22:32:05,593 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
2020-04-27 22:32:05,646 INFO namenode.FSDirectory: GLOBAL serial map: bits=29 maxEntries=536870911
2020-04-27 22:32:05,646 INFO namenode.FSDirectory: USER serial map: bits=24 maxEntries=16777215
2020-04-27 22:32:05,647 INFO namenode.FSDirectory: GROUP serial map: bits=24 maxEntries=16777215
2020-04-27 22:32:05,647 INFO namenode.FSDirectory: XATTR serial map: bits=24 maxEntries=16777215
2020-04-27 22:32:05,664 INFO util.GSet: Computing capacity for map INodeMap
2020-04-27 22:32:05,664 INFO util.GSet: VM type = 64-bit
2020-04-27 22:32:05,664 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB
2020-04-27 22:32:05,665 INFO util.GSet: capacity = 2^20 = 1048576 entries
2020-04-27 22:32:05,666 INFO namenode.FSDirectory: ACLs enabled? false
2020-04-27 22:32:05,666 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true
2020-04-27 22:32:05,667 INFO namenode.FSDirectory: XAttrs enabled? true
2020-04-27 22:32:05,667 INFO namenode.NameNode: Caching file names occurring more than 10 times
2020-04-27 22:32:05,674 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2020-04-27 22:32:05,677 INFO snapshot.SnapshotManager: SkipList is disabled
2020-04-27 22:32:05,681 INFO util.GSet: Computing capacity for map cachedBlocks
2020-04-27 22:32:05,681 INFO util.GSet: VM type = 64-bit
2020-04-27 22:32:05,682 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB
2020-04-27 22:32:05,683 INFO util.GSet: capacity = 2^18 = 262144 entries
2020-04-27 22:32:05,713 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2020-04-27 22:32:05,714 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2020-04-27 22:32:05,714 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2020-04-27 22:32:05,720 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2020-04-27 22:32:05,721 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2020-04-27 22:32:05,723 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2020-04-27 22:32:05,723 INFO util.GSet: VM type = 64-bit
2020-04-27 22:32:05,724 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
2020-04-27 22:32:05,724 INFO util.GSet: capacity = 2^15 = 32768 entries
2020-04-27 22:32:05,765 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1264791665-192.168.10.2-1588008725757
2020-04-27 22:32:05,810 INFO common.Storage: Storage directory E:\big-data\data\dfs\namespace_logs has been successfully formatted.
2020-04-27 22:32:05,841 INFO namenode.FSImageFormatProtobuf: Saving image file E:\big-data\data\dfs\namespace_logs\current\fsimage.ckpt_0000000000000000000 using no compression
2020-04-27 22:32:05,939 INFO namenode.FSImageFormatProtobuf: Image file E:\big-data\data\dfs\namespace_logs\current\fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2020-04-27 22:32:05,957 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-04-27 22:32:05,963 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2020-04-27 22:32:05,963 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at DESKTOP-ROC4R5P/192.168.10.2
************************************************************/
i have downloaded jar and put in folder also.
https://github.com/FahaoTang/big-data/blob/master/hadoop-hdfs-3.2.1.jar
Can you help me what thing i am setting wrong??? it will be great help and guidance.
Regards,
Saad
Hi Saad,
I don't see any error message in the log you pasted.
Can you please be more specific about the errors you encounterred.
For formatting namenode, it is correct to expect the namenode daemon to shutdown after the format is done. We will start all the HDFS and YAN daemons at the end.
Hi,
http://localhost:9870/dfshealth.html#tab-overview
http://localhost:9864/datanode.html
these 2 links were not opening once i reached till end, then i started changing values in hdfs-site.xml
to some other paths locations in E drive and then i think got lost.
Today when i run start-dfs.cmd then data and name node start without any error and i can see above 2 urls without any error.
Thanks for quick reply.
Can you also guide me where can i find and change ports values like 8088,9870 etc.
Thanks again for this tutorial.
Regards,
Saad
Hi Saad,
Refer to the Reference section on this page: Default Ports Used by Hadoop Services (HDFS, MapReduce, YARN). It has the links to the official documentation about all the parameters you can configure in HDFS and YARN. It also shows the default values for each configurations.
For different versions of Hadoop, the default values might be different.
When i type winutils.exe anr run
getting this error
winutils.exe : The term 'winutils.exe' is not recognized as the name of a cmdlet, function, script file, or operable
program. Check the spelling of the name, or if a path was included, verify that the path is correct and try again.
At line:1 char:1
+ winutils.exe
+ ~~~~~~~~~~~~
+ CategoryInfo : ObjectNotFound: (winutils.exe:String) [], CommandNotFoundException
+ FullyQualifiedErrorId : CommandNotFoundException
what to do
Did you follow step 3?
Step 3 - Install Hadoop native IO binary
If you've done that, you should be able to see the exe file in %HADOOP_HOME%/bin folder:
And also make sure HADOOP_HOME environment variable is configured correctly and also PATH environment variable has Hadoop bin folder.
You also need to restart PowerShell to source the latest environment variables if you are configure all these variables manually.
Please let me know if that still exists.
Hi Raymond!
First of all: many thanks – a great how-to saving me hours! Well, almost, that is.
I tried to install Hadoop 3.2.1 using your article. Everything went like a charm, I did encounter the problem mentioned when formatting the HDFS, the workaround worked fine.
However, when I reached Step 10 (launch YARN), both command windows run into a runtime exception. (See below)
The OS is a Windows 10 Edu N (english) and is up to date (as of today, Jan 25). The JDK is 13.0.1.
Any hint would be very much appreciated, as I'm far from being able to make sense of the messages!
Cheers from Vienna/Austria
Matthew
2020-01-25 15:54:39,323 INFO resourcemanager.ResourceManager: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting ResourceManager
STARTUP_MSG: host = pitdb/10.0.2.15
STARTUP_MSG: args = []
STARTUP_MSG: version = 3.2.1
STARTUP_MSG: classpath = C:\hadoop-3.2.1\etc\hadoop;C:\hadoop-3.2.1\etc\hadoop;C:\hadoop-3.2.1\etc\hadoop;C:\hadoop-3.2.1\share\hadoop\common;C:\hadoop-3.2.1\share\hadoop\common\lib\accessors-smart-1.2.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\animal-sniffer-annotations-1.17.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\asm-5.0.4.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\audience-annotations-0.5.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\avro-1.7.7.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\checker-qual-2.5.2.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-beanutils-1.9.3.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-cli-1.2.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-codec-1.11.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-collections-3.2.2.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-compress-1.18.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-configuration2-2.1.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-io-2.5.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-lang3-3.7.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-logging-1.1.3.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-math3-3.1.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-net-3.6.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\commons-text-1.4.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\curator-client-2.13.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\curator-framework-2.13.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\curator-recipes-2.13.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\dnsjava-2.1.7.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\error_prone_annotations-2.2.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\failureaccess-1.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\gson-2.2.4.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\guava-27.0-jre.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\hadoop-annotations-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\hadoop-auth-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\htrace-core4-4.1.0-incubating.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\httpclient-4.5.6.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\httpcore-4.4.10.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\j2objc-annotations-1.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jackson-annotations-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jackson-core-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jackson-core-asl-1.9.13.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jackson-databind-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jackson-jaxrs-1.9.13.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jackson-mapper-asl-1.9.13.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jackson-xc-1.9.13.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\javax.servlet-api-3.1.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jaxb-api-2.2.11.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jaxb-impl-2.2.3-1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jcip-annotations-1.0-1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jersey-core-1.19.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jersey-json-1.19.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jersey-server-1.19.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jersey-servlet-1.19.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jettison-1.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jetty-http-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jetty-io-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jetty-security-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jetty-server-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jetty-servlet-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jetty-util-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jetty-webapp-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jetty-xml-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jsch-0.1.54.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\json-smart-2.3.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jsp-api-2.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jsr305-3.0.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jsr311-api-1.1.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\jul-to-slf4j-1.7.25.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-admin-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-client-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-common-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-core-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-crypto-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-identity-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-server-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-simplekdc-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerb-util-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerby-asn1-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerby-config-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerby-pkix-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerby-util-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\kerby-xdr-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\log4j-1.2.17.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\metrics-core-3.2.4.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\netty-3.10.5.Final.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\nimbus-jose-jwt-4.41.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\paranamer-2.3.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\protobuf-java-2.5.0.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\re2j-1.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\slf4j-api-1.7.25.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\slf4j-log4j12-1.7.25.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\snappy-java-1.0.5.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\stax2-api-3.1.4.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\token-provider-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\woodstox-core-5.0.3.jar;C:\hadoop-3.2.1\share\hadoop\common\lib\zookeeper-3.4.13.jar;C:\hadoop-3.2.1\share\hadoop\common\hadoop-common-3.2.1-tests.jar;C:\hadoop-3.2.1\share\hadoop\common\hadoop-common-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\common\hadoop-kms-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\common\hadoop-nfs-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\accessors-smart-1.2.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\animal-sniffer-annotations-1.17.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\asm-5.0.4.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\audience-annotations-0.5.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\avro-1.7.7.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\checker-qual-2.5.2.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-beanutils-1.9.3.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-cli-1.2.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-codec-1.11.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-collections-3.2.2.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-compress-1.18.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-configuration2-2.1.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-daemon-1.0.13.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-io-2.5.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-lang3-3.7.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-logging-1.1.3.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-math3-3.1.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-net-3.6.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\commons-text-1.4.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\curator-client-2.13.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\curator-framework-2.13.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\curator-recipes-2.13.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\dnsjava-2.1.7.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\error_prone_annotations-2.2.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\failureaccess-1.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\gson-2.2.4.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\guava-27.0-jre.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\hadoop-annotations-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\hadoop-auth-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\htrace-core4-4.1.0-incubating.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\httpclient-4.5.6.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\httpcore-4.4.10.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\j2objc-annotations-1.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jackson-annotations-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jackson-core-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jackson-core-asl-1.9.13.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jackson-databind-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jackson-jaxrs-1.9.13.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jackson-mapper-asl-1.9.13.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jackson-xc-1.9.13.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\javax.servlet-api-3.1.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jaxb-api-2.2.11.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jaxb-impl-2.2.3-1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jcip-annotations-1.0-1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jersey-core-1.19.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jersey-json-1.19.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jersey-server-1.19.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jersey-servlet-1.19.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jettison-1.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-http-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-io-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-security-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-server-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-servlet-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-util-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-util-ajax-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-webapp-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jetty-xml-9.3.24.v20180605.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jsch-0.1.54.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\json-simple-1.1.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\json-smart-2.3.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jsr305-3.0.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\jsr311-api-1.1.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-admin-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-client-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-common-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-core-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-crypto-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-identity-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-server-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-simplekdc-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerb-util-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerby-asn1-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerby-config-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerby-pkix-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerby-util-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\kerby-xdr-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\leveldbjni-all-1.8.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\log4j-1.2.17.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\netty-3.10.5.Final.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\netty-all-4.0.52.Final.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\nimbus-jose-jwt-4.41.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\okhttp-2.7.5.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\okio-1.6.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\paranamer-2.3.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\protobuf-java-2.5.0.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\re2j-1.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\snappy-java-1.0.5.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\stax2-api-3.1.4.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\token-provider-1.0.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\woodstox-core-5.0.3.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\lib\zookeeper-3.4.13.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-3.2.1-tests.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-client-3.2.1-tests.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-client-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-httpfs-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-native-client-3.2.1-tests.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-native-client-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-nfs-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-rbf-3.2.1-tests.jar;C:\hadoop-3.2.1\share\hadoop\hdfs\hadoop-hdfs-rbf-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn;C:\hadoop-3.2.1\share\hadoop\yarn\lib\aopalliance-1.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\bcpkix-jdk15on-1.60.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\bcprov-jdk15on-1.60.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\ehcache-3.3.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\fst-2.50.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\geronimo-jcache_1.0_spec-1.0-alpha-1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\guice-4.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\guice-servlet-4.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\HikariCP-java7-2.4.12.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jackson-jaxrs-base-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jackson-jaxrs-json-provider-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jackson-module-jaxb-annotations-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\java-util-1.9.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\javax.inject-1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jersey-client-1.19.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jersey-guice-1.19.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\json-io-2.5.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\metrics-core-3.2.4.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\mssql-jdbc-6.2.1.jre7.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\objenesis-1.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\snakeyaml-1.16.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\swagger-annotations-1.5.4.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-api-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-applications-distributedshell-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-applications-unmanaged-am-launcher-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-client-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-common-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-registry-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-applicationhistoryservice-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-common-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-nodemanager-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-resourcemanager-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-router-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-sharedcachemanager-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-tests-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-timeline-pluginstorage-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-web-proxy-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-services-api-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-services-core-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-submarine-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\lib\hamcrest-core-1.3.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\lib\junit-4.11.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-app-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-common-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-core-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-hs-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-hs-plugins-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-jobclient-3.2.1-tests.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-jobclient-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-nativetask-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-shuffle-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-client-uploader-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\mapreduce\hadoop-mapreduce-examples-3.2.1.jar;C:\hadoop-2.7.7\etc\hadoop;C:\hadoop-2.7.7\lib;C:\hadoop-2.7.7\share\hadoop\common;C:\hadoop-2.7.7\share\hadoop\common\;C:\hadoop-2.7.7\share\hadoop\common\*;C:\hadoop-2.7.7\share\hadoop\common\lib\*;C:\hadoop-2.7.7\share\hadoop\hdfs;C:\hadoop-2.7.7\share\hadoop\hdfs\*;C:\hadoop-2.7.7\share\hadoop\hdfs\lib\*;C:\hadoop-2.7.7\share\hadoop\yarn\*;C:\hadoop-2.7.7\share\hadoop\yarn\lib\*;C:\hadoop-2.7.7\share\hadoop\mapreduce;C:\hadoop-2.7.7\share\hadoop\mapreduce\*;C:\hadoop-2.7.7\share\hadoop\mapreduce\lib\*;C:\Users\user\Desktop\hadoop\units.jar;C:\Users\user\Desktop\hadoop\wc.jar;;;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-api-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-applications-distributedshell-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-applications-unmanaged-am-launcher-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-client-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-common-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-registry-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-applicationhistoryservice-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-common-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-nodemanager-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-resourcemanager-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-router-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-sharedcachemanager-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-tests-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-timeline-pluginstorage-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-server-web-proxy-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-services-api-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-services-core-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\hadoop-yarn-submarine-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\aopalliance-1.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\bcpkix-jdk15on-1.60.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\bcprov-jdk15on-1.60.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\ehcache-3.3.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\fst-2.50.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\geronimo-jcache_1.0_spec-1.0-alpha-1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\guice-4.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\guice-servlet-4.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\HikariCP-java7-2.4.12.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jackson-jaxrs-base-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jackson-jaxrs-json-provider-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jackson-module-jaxb-annotations-2.9.8.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\java-util-1.9.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\javax.inject-1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jersey-client-1.19.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\jersey-guice-1.19.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\json-io-2.5.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\metrics-core-3.2.4.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\mssql-jdbc-6.2.1.jre7.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\objenesis-1.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\snakeyaml-1.16.jar;C:\hadoop-3.2.1\share\hadoop\yarn\lib\swagger-annotations-1.5.4.jar;C:\hadoop-3.2.1\etc\hadoop\rm-config\log4j.properties;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\hadoop-yarn-server-timelineservice-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\hadoop-yarn-server-timelineservice-hbase-client-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\hadoop-yarn-server-timelineservice-hbase-common-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\hadoop-yarn-server-timelineservice-hbase-coprocessor-3.2.1.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\commons-csv-1.0.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\commons-lang-2.6.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\hbase-annotations-1.2.6.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\hbase-client-1.2.6.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\hbase-common-1.2.6.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\hbase-protocol-1.2.6.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\htrace-core-3.1.0-incubating.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\jcodings-1.0.13.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\joni-2.1.2.jar;C:\hadoop-3.2.1\share\hadoop\yarn\timelineservice\lib\metrics-core-2.2.0.jar
STARTUP_MSG: build = https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842; compiled by 'rohithsharmaks' on 2019-09-10T15:56Z
STARTUP_MSG: java = 13.0.1
************************************************************/
2020-01-25 15:54:41,357 INFO conf.Configuration: found resource core-site.xml at file:/C:/hadoop-3.2.1/etc/hadoop/core-site.xml
2020-01-25 15:54:42,042 INFO conf.Configuration: resource-types.xml not found
2020-01-25 15:54:42,042 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2020-01-25 15:54:42,386 INFO conf.Configuration: found resource yarn-site.xml at file:/C:/hadoop-3.2.1/etc/hadoop/yarn-site.xml
2020-01-25 15:54:42,542 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.RMFatalEventType for class org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$RMFatalEventDispatcher
2020-01-25 15:54:42,698 INFO security.NMTokenSecretManagerInRM: NMTokenKeyRollingInterval: 86400000ms and NMTokenKeyActivationDelay: 900000ms
2020-01-25 15:54:42,714 INFO security.RMContainerTokenSecretManager: ContainerTokenKeyRollingInterval: 86400000ms and ContainerTokenKeyActivationDelay: 900000ms
2020-01-25 15:54:42,730 INFO security.AMRMTokenSecretManager: AMRMTokenKeyRollingInterval: 86400000ms and AMRMTokenKeyActivationDelay: 900000 ms
2020-01-25 15:54:42,792 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.recovery.RMStateStoreEventType for class org.apache.hadoop.yarn.server.resourcemanager.recovery.RMStateStore$ForwardingEventHandler
2020-01-25 15:54:42,792 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.NodesListManagerEventType for class org.apache.hadoop.yarn.server.resourcemanager.NodesListManager
2020-01-25 15:54:42,839 INFO resourcemanager.ResourceManager: Using Scheduler: org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
2020-01-25 15:54:42,979 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.scheduler.event.SchedulerEventType for class org.apache.hadoop.yarn.event.EventDispatcher
2020-01-25 15:54:43,026 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppEventType for class org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$ApplicationEventDispatcher
2020-01-25 15:54:43,104 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptEventType for class org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$ApplicationAttemptEventDispatcher
2020-01-25 15:54:43,104 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNodeEventType for class org.apache.hadoop.yarn.server.resourcemanager.ResourceManager$NodeEventDispatcher
2020-01-25 15:54:43,666 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2020-01-25 15:54:44,025 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2020-01-25 15:54:44,042 INFO impl.MetricsSystemImpl: ResourceManager metrics system started
2020-01-25 15:54:44,119 INFO security.YarnAuthorizationProvider: org.apache.hadoop.yarn.security.ConfiguredYarnAuthorizer is instantiated.
2020-01-25 15:54:44,151 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.RMAppManagerEventType for class org.apache.hadoop.yarn.server.resourcemanager.RMAppManager
2020-01-25 15:54:44,166 INFO event.AsyncDispatcher: Registering class org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncherEventType for class org.apache.hadoop.yarn.server.resourcemanager.amlauncher.ApplicationMasterLauncher
2020-01-25 15:54:44,182 INFO resourcemanager.RMNMInfo: Registered RMNMInfo MBean
2020-01-25 15:54:44,198 INFO monitor.RMAppLifetimeMonitor: Application lifelime monitor interval set to 3000 ms.
2020-01-25 15:54:44,198 INFO placement.MultiNodeSortingManager: Initializing NodeSortingService=MultiNodeSortingManager
2020-01-25 15:54:44,261 INFO util.HostsFileReader: Refreshing hosts (include/exclude) list
2020-01-25 15:54:44,308 INFO conf.Configuration: found resource capacity-scheduler.xml at file:/C:/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml
2020-01-25 15:54:44,448 INFO scheduler.AbstractYarnScheduler: Minimum allocation = <memory:1024, vCores:1>
2020-01-25 15:54:44,464 INFO scheduler.AbstractYarnScheduler: Maximum allocation = <memory:8192, vCores:4>
2020-01-25 15:54:44,605 INFO capacity.CapacitySchedulerConfiguration: max alloc mb per queue for root is undefined
2020-01-25 15:54:44,682 INFO capacity.CapacitySchedulerConfiguration: max alloc vcore per queue for root is undefined
2020-01-25 15:54:44,776 INFO capacity.ParentQueue: root, capacity=1.0, absoluteCapacity=1.0, maxCapacity=1.0, absoluteMaxCapacity=1.0, state=RUNNING, acls=ADMINISTER_QUEUE:*SUBMIT_APP:*, labels=*,
, reservationsContinueLooking=true, orderingPolicy=utilization, priority=0
2020-01-25 15:54:44,808 INFO capacity.ParentQueue: Initialized parent-queue root name=root, fullname=root
2020-01-25 15:54:44,902 INFO capacity.CapacitySchedulerConfiguration: max alloc mb per queue for root.default is undefined
2020-01-25 15:54:45,011 INFO capacity.CapacitySchedulerConfiguration: max alloc vcore per queue for root.default is undefined
2020-01-25 15:54:45,089 INFO capacity.LeafQueue: Initializing default
capacity = 1.0 [= (float) configuredCapacity / 100 ]
absoluteCapacity = 1.0 [= parentAbsoluteCapacity * capacity ]
maxCapacity = 1.0 [= configuredMaxCapacity ]
absoluteMaxCapacity = 1.0 [= 1.0 maximumCapacity undefined, (parentAbsoluteMaxCapacity * maximumCapacity) / 100 otherwise ]
effectiveMinResource=<memory:0, vCores:0>
, effectiveMaxResource=<memory:0, vCores:0>
userLimit = 100 [= configuredUserLimit ]
userLimitFactor = 1.0 [= configuredUserLimitFactor ]
maxApplications = 10000 [= configuredMaximumSystemApplicationsPerQueue or (int)(configuredMaximumSystemApplications * absoluteCapacity)]
maxApplicationsPerUser = 10000 [= (int)(maxApplications * (userLimit / 100.0f) * userLimitFactor) ]
usedCapacity = 0.0 [= usedResourcesMemory / (clusterResourceMemory * absoluteCapacity)]
absoluteUsedCapacity = 0.0 [= usedResourcesMemory / clusterResourceMemory]
maxAMResourcePerQueuePercent = 0.1 [= configuredMaximumAMResourcePercent ]
minimumAllocationFactor = 0.875 [= (float)(maximumAllocationMemory - minimumAllocationMemory) / maximumAllocationMemory ]
maximumAllocation = <memory:8192, vCores:4> [= configuredMaxAllocation ]
numContainers = 0 [= currentNumContainers ]
state = RUNNING [= configuredState ]
acls = ADMINISTER_QUEUE:*SUBMIT_APP:* [= configuredAcls ]
nodeLocalityDelay = 40
rackLocalityAdditionalDelay = -1
labels=*,
reservationsContinueLooking = true
preemptionDisabled = true
defaultAppPriorityPerQueue = 0
priority = 0
maxLifetime = -1 seconds
defaultLifetime = -1 seconds
2020-01-25 15:54:45,152 INFO capacity.CapacitySchedulerQueueManager: Initialized queue: default: capacity=1.0, absoluteCapacity=1.0, usedResources=<memory:0, vCores:0>, usedCapacity=0.0, absoluteUsedCapacity=0.0, numApps=0, numContainers=0, effectiveMinResource=<memory:0, vCores:0> , effectiveMaxResource=<memory:0, vCores:0>
2020-01-25 15:54:45,167 INFO capacity.CapacitySchedulerQueueManager: Initialized queue: root: numChildQueue= 1, capacity=1.0, absoluteCapacity=1.0, usedResources=<memory:0, vCores:0>usedCapacity=0.0, numApps=0, numContainers=0
2020-01-25 15:54:45,167 INFO capacity.CapacitySchedulerQueueManager: Initialized root queue root: numChildQueue= 1, capacity=1.0, absoluteCapacity=1.0, usedResources=<memory:0, vCores:0>usedCapacity=0.0, numApps=0, numContainers=0
2020-01-25 15:54:45,167 INFO placement.UserGroupMappingPlacementRule: Initialized queue mappings, override: false
2020-01-25 15:54:45,167 INFO placement.MultiNodeSortingManager: MultiNode scheduling is 'false', and configured policies are
2020-01-25 15:54:45,197 INFO capacity.CapacityScheduler: Initialized CapacityScheduler with calculator=class org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator, minimumAllocation=<<memory:1024, vCores:1>>, maximumAllocation=<<memory:8192, vCores:4>>, asynchronousScheduling=false, asyncScheduleInterval=5ms,multiNodePlacementEnabled=false
2020-01-25 15:54:45,197 INFO conf.Configuration: dynamic-resources.xml not found
2020-01-25 15:54:45,213 INFO resourcemanager.AMSProcessingChain: Initializing AMS Processing chain. Root Processor=[org.apache.hadoop.yarn.server.resourcemanager.DefaultAMSProcessor].
2020-01-25 15:54:45,213 INFO resourcemanager.ApplicationMasterService: disabled placement handler will be used, all scheduling requests will be rejected.
2020-01-25 15:54:45,213 INFO resourcemanager.AMSProcessingChain: Adding [org.apache.hadoop.yarn.server.resourcemanager.scheduler.constraint.processor.DisabledPlacementProcessor] tp top of AMS Processing chain.
2020-01-25 15:54:45,229 INFO resourcemanager.ResourceManager: TimelineServicePublisher is not configured
2020-01-25 15:54:45,291 INFO util.log: Logging initialized @8928ms
2020-01-25 15:54:45,400 INFO server.AuthenticationFilter: Unable to initialize FileSignerSecretProvider, falling back to use random secrets.
2020-01-25 15:54:45,417 INFO http.HttpRequestLog: Http request log for http.requests.resourcemanager is not defined
2020-01-25 15:54:45,432 INFO http.HttpServer2: Added global filter 'safety' (class=org.apache.hadoop.http.HttpServer2$QuotingInputFilter)
2020-01-25 15:54:45,432 INFO http.HttpServer2: Added filter RMAuthenticationFilter (class=org.apache.hadoop.yarn.server.security.http.RMAuthenticationFilter) to context cluster
2020-01-25 15:54:45,432 INFO http.HttpServer2: Added filter RMAuthenticationFilter (class=org.apache.hadoop.yarn.server.security.http.RMAuthenticationFilter) to context static
2020-01-25 15:54:45,432 INFO http.HttpServer2: Added filter RMAuthenticationFilter (class=org.apache.hadoop.yarn.server.security.http.RMAuthenticationFilter) to context logs
2020-01-25 15:54:45,448 INFO http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context cluster
2020-01-25 15:54:45,448 INFO http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context static
2020-01-25 15:54:45,448 INFO http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context logs
2020-01-25 15:54:45,448 INFO http.HttpServer2: adding path spec: /cluster/*
2020-01-25 15:54:45,448 INFO http.HttpServer2: adding path spec: /ws/*
2020-01-25 15:54:45,448 INFO http.HttpServer2: adding path spec: /app/*
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by com.google.inject.internal.cglib.core.$ReflectUtils$2 (file:/C:/hadoop-3.2.1/share/hadoop/yarn/lib/guice-4.0.jar) to method java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain)
WARNING: Please consider reporting this to the maintainers of com.google.inject.internal.cglib.core.$ReflectUtils$2
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2020-01-25 15:54:47,277 INFO webapp.WebApps: Registered webapp guice modules
2020-01-25 15:54:47,402 INFO http.HttpServer2: Jetty bound to port 8088
2020-01-25 15:54:47,574 INFO server.Server: jetty-9.3.24.v20180605, build timestamp: 2018-06-05T19:11:56+02:00, git hash: 84205aa28f11a4f31f2a3b86d1bba2cc8ab69827
2020-01-25 15:54:47,885 INFO server.AuthenticationFilter: Unable to initialize FileSignerSecretProvider, falling back to use random secrets.
2020-01-25 15:54:47,964 INFO delegation.AbstractDelegationTokenSecretManager: Updating the current master key for generating delegation tokens
2020-01-25 15:54:48,057 INFO delegation.AbstractDelegationTokenSecretManager: Starting expired delegation token remover thread, tokenRemoverScanInterval=60 min(s)
2020-01-25 15:54:48,136 INFO handler.ContextHandler: Started o.e.j.s.ServletContextHandler@53ab0286{/logs,file:///C:/hadoop-3.2.1/logs/,AVAILABLE}
2020-01-25 15:54:48,230 INFO delegation.AbstractDelegationTokenSecretManager: Updating the current master key for generating delegation tokens
2020-01-25 15:54:48,479 INFO handler.ContextHandler: Started o.e.j.s.ServletContextHandler@2ce86164{/static,jar:file:/C:/hadoop-3.2.1/share/hadoop/yarn/hadoop-yarn-common-3.2.1.jar!/webapps/static,AVAILABLE}
Jõn. 25, 2020 3:54:49 PM com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory register
INFO: Registering org.apache.hadoop.yarn.server.resourcemanager.webapp.JAXBContextResolver as a provider class
Jõn. 25, 2020 3:54:49 PM com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory register
INFO: Registering org.apache.hadoop.yarn.server.resourcemanager.webapp.RMWebServices as a root resource class
Jõn. 25, 2020 3:54:49 PM com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory register
INFO: Registering org.apache.hadoop.yarn.webapp.GenericExceptionHandler as a provider class
Jõn. 25, 2020 3:54:49 PM com.sun.jersey.server.impl.application.WebApplicationImpl _initiate
INFO: Initiating Jersey application, version 'Jersey: 1.19 02/11/2015 03:25 AM'
Jõn. 25, 2020 3:54:50 PM com.sun.jersey.guice.spi.container.GuiceComponentProviderFactory getComponentProvider
INFO: Binding org.apache.hadoop.yarn.server.resourcemanager.webapp.JAXBContextResolver to GuiceManagedComponentProvider with the scope "Singleton"
2020-01-25 15:54:50,729 WARN webapp.WebAppContext: Failed startup of context o.e.j.w.WebAppContext@4422dd48{/,file:///C:/Users/user/AppData/Local/Temp/jetty-0.0.0.0-8088-cluster-_-any-4591039387602299968.dir/webapp/,UNAVAILABLE}{/cluster}
com.google.inject.ProvisionException: Unable to provision, see the following errors:
1) Error injecting constructor, java.lang.NoClassDefFoundError: javax/activation/DataSource
at org.apache.hadoop.yarn.server.resourcemanager.webapp.JAXBContextResolver.<init>(JAXBContextResolver.java:41)
at org.apache.hadoop.yarn.server.resourcemanager.webapp.RMWebApp.setup(RMWebApp.java:54)
while locating org.apache.hadoop.yarn.server.resourcemanager.webapp.JAXBContextResolver
1 error
at com.google.inject.internal.InjectorImpl$2.get(InjectorImpl.java:1025)
at com.google.inject.internal.InjectorImpl.getInstance(InjectorImpl.java:1051)
Hi Matthias,
As far as I know, JDK 13.0.1 is not supported.
Please use JDK 1.8.x, it will work.
Even JDK 11 support is still in progress.
https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
Hello Raymond,
you nailed it! Everything
works fine now (except, I feel somewhat stupid, for I knew about JDK8,
but for some reason assumed this to be but a minimum requirement. It
didn't occur to me to revert to the older version. Let's hope, this will save someone at least something.)
Thanks a lot!
Cheers,
Matthias
I'm glad it worked. I also updated the page to reflect the JDK requirement.
BTW, if you want to build a native Hadoop 3.2.1 on Windows, you can follow this guide:
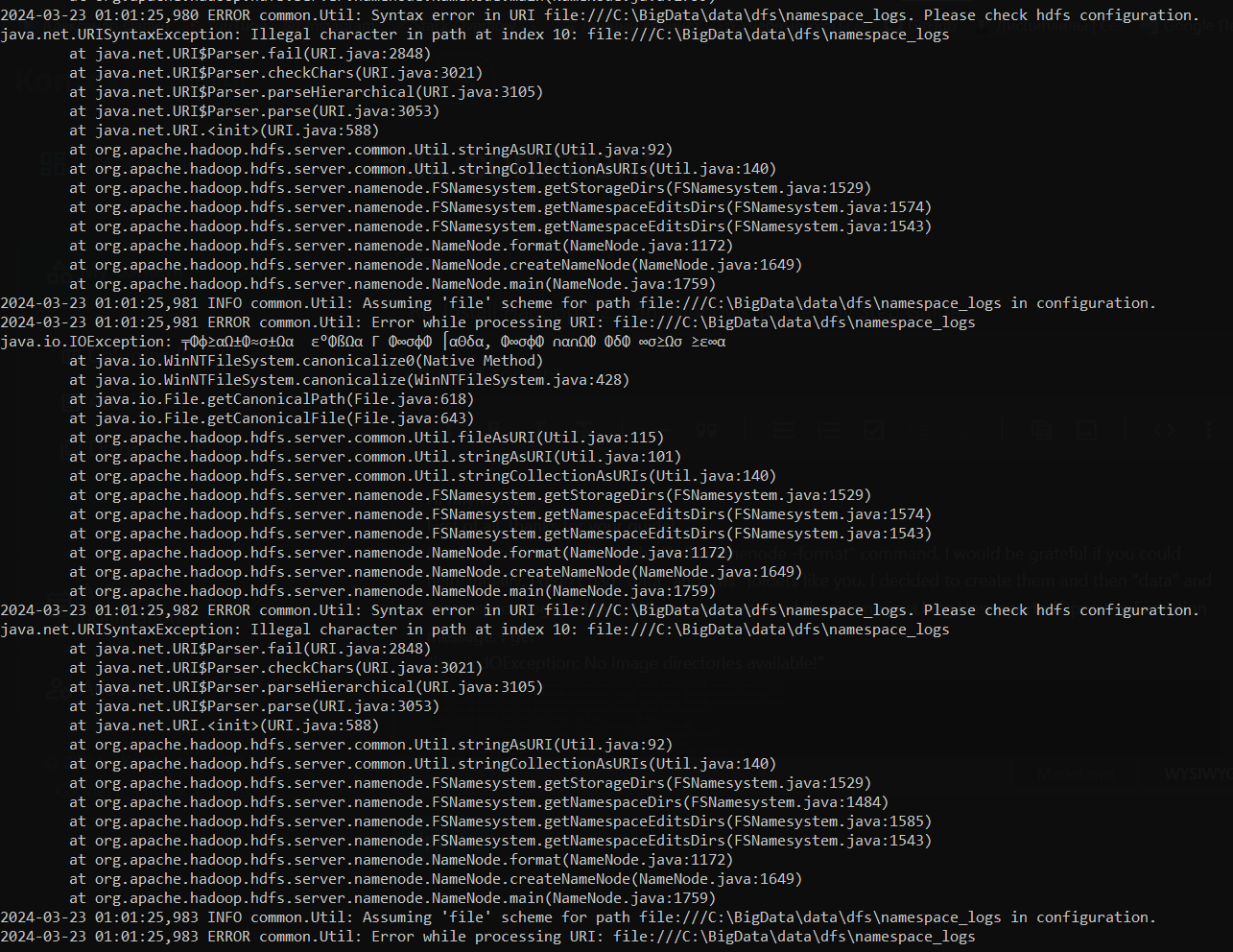
Hi Raymond!
First of all, thanks for your guide!
I had a problem initializing the "hdfs namenode -format" command. I would be grateful if you could help. Initially, I didn't had "data" and "dfs" folders like you. I decided to create them and then "data" and "namespace_logs" folders. When I use command there is no java.lang.UnsupportedOperationException message. I get
"java.io.IOException: No image directories available!" Also I get errors related to URI