Kontext Platform includes a serverless job execution framework for background processing. Use it to run data analysis, AI workloads, and scheduled or event-driven workflows.
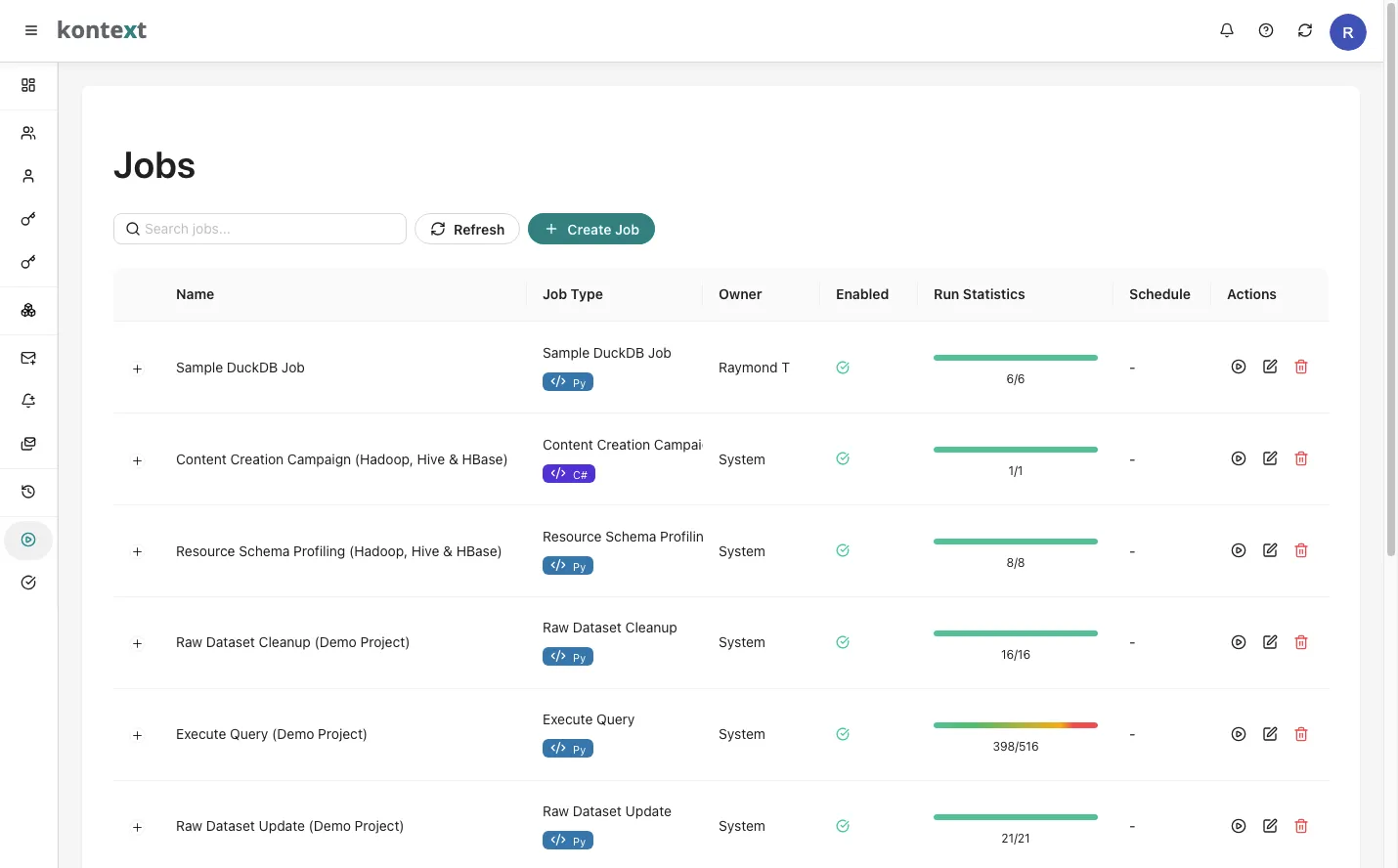
Overview
The serverless job framework is designed to handle compute-intensive tasks that require reliable execution, monitoring, and scaling capabilities. Whether you’re processing large datasets, running machine learning models, or executing complex business workflows, our framework provides the infrastructure you need.
Key Features
Serverless Architecture
Our job framework is built from the ground up for cloud environments:
- Functions Integration: Native support for Azure Functions for serverless execution and support for AWS Lambda is WIP.
- Auto-scaling: Automatically scales based on workload demands
- Cost-Effective: Pay only for actual compute time used
- Global Distribution: Run jobs in multiple regions for optimal performance
Reliable Job Execution
Ensure your critical tasks complete successfully:
- Retry Logic: Configurable retry policies for failed jobs
- Error Handling: Comprehensive error tracking and reporting
- Dead Letter Queues: Automatic handling of persistently failing jobs
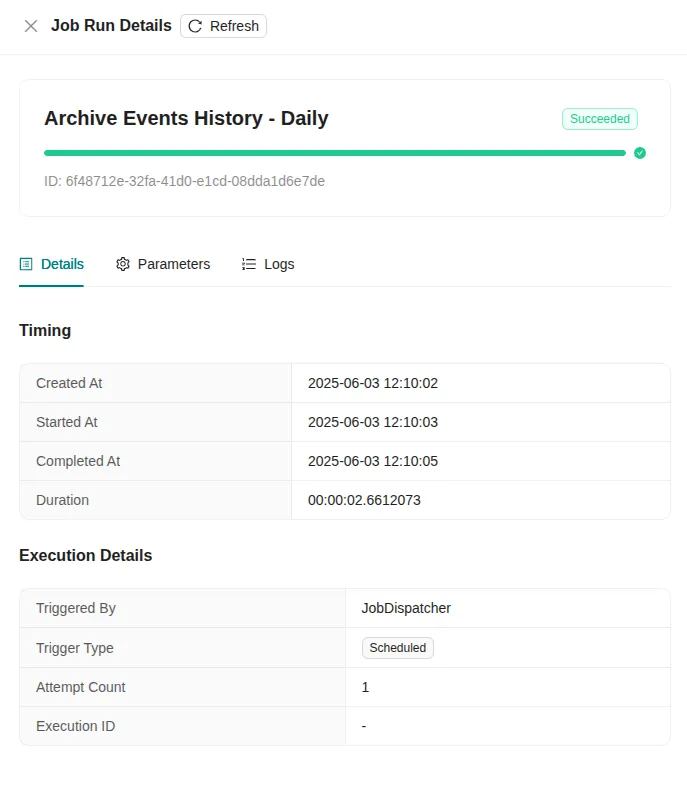
- Monitoring: Real-time job status and performance monitoring
Multiple Job Workers
Kontext Platform currently support two types of Job workers:
- C# Job: For system and platform level tasks.
- Python Job: For data processing and generic tasks. All AI jobs are also executed by Python job workers.
Queue-Based Processing
Robust job queuing system for reliable task management:
- Azure Storage Queues: Durable message queuing for job coordination
- Priority Queues: Execute high-priority jobs first
- Batch Processing: Group related jobs for efficient execution
- Schedule Management: Support for recurring and scheduled jobs
Supported Job Types
Data Processing Jobs
Transform and analyze your data at scale:
- ETL Pipelines: Extract, transform, and load data between systems
- Data Validation: Validate data quality and integrity
- File Processing: Process uploaded files and documents
- Data Aggregation: Create summaries and reports from raw data
Data Lake Queries
All SQL query on Kontext Data Lake are executed by the job framework.
Machine Learning Workflows
Run AI and ML workloads efficiently:
- Model Training: Train machine learning models on your data
- Batch Inference: Run predictions on large datasets
- Feature Engineering: Create and transform features for ML models
- Model Evaluation: Assess model performance and accuracy
Integration Tasks
Connect with external systems and services:
- API Synchronization: Sync data with third-party APIs
- Database Migrations: Move data between different systems
- File Transfers: Automated file uploading and downloading
- Webhook Processing: Handle incoming webhook notifications
Custom Workflows
Build specialized business logic:
- Report Generation: Create automated reports and dashboards
- Notification Systems: Send emails, SMS, and push notifications
- Content Processing: Process and analyze text, images, and documents
GenAI Workflows
Leverage the power of Generative AI and modern NLP techniques:
- Embedding Generation: Create vector embeddings for text, documents, and multimedia content
- Semantic Search Indexing: Build and maintain vector databases for semantic search workflows
- Document Summarization: Generate concise summaries of large documents and datasets
- Content Generation: Create automated content using large language models
How Jobs Start
Kontext job instances can be started in three main ways:
- Manually: Administrators can kick off jobs themselves using the user interface or an API. This requires the correct permissions.
- Scheduled: Jobs can run automatically based on a set schedule, like every hour, day, or week (using a CORN-based schedule).
- Event-Driven: Certain actions or events within the platform can automatically trigger jobs.